Self-updating build servers, automatically
🎃 It’s Friday the 13th - let’s talk questionable, but effective, ideas 👻
Your build infrastructure can update itself using your own CI tooling. It’s easier and way better than it sounds, especially at scales that don’t justify hiring dedicated teams of engineers to run it. Hear me out …
No one will argue that keeping your infrastructure up to date is important to your company’s security posture. Yet, I’ve noticed this is a common oversight for build servers specifically.1
It’s way less risky to simply update everything on these machines from the default repositories for that OS, then reboot, once a week (ish). To the folks mad at that suggestion, please head to the footnotes2. With big fleets of infrastructure, this gets done with tools designed to do exactly that task - Ansible , Puppet , Red Hat Satellite , etc. These tools are great for teams that have invested time and energy into building and maintaining them, but …
🤔 What if you need something a little simpler?
Self-updating CI servers
Running OS updates on my self-hosted runners using GitHub Actions itself is surprisingly effective.3 Here’s the workflow jobs (full file ) with the runs-on target changed out:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
apt-updates:
runs-on: (target tag)
steps:
- name: Update the apt cache
shell: bash
run: |
sudo apt clean
sudo apt update
- name: Run all package updates
shell: bash
env:
DEBIAN_FRONTEND: noninteractive
run: sudo apt dist-upgrade -y
- name: Reboot
shell: bash
run: sudo shutdown -r +1 "Rebooting ... brb"
wait:
name: wait for 5 minutes
runs-on: ubuntu-latest # using GitHub's hosted runners here, just can't be the tag that updated for self-hosted only environments
needs: [apt-updates]
steps:
- name: wait for 5 minutes
shell: bash
run: sleep 300
check-its-back-up:
runs-on: (target tag)
name: Verify everything is back up and online
needs: [wait]
steps:
- name: Verify we're back online and have rebooted less than 10 minutes ago
shell: bash
run: |
secs="$(awk '{print $1}' /proc/uptime | sed 's/\.[^\.]*$//')"
if [ "$secs" -lt 600 ]; then
echo "System rebooted less than 10 minutes ago"
exit 0
else
echo "System rebooted more than 10 minutes ago"
exit 1
fi
This is surprisingly good! Staying on the latest updates within Raspberry Pi OS (or any Debian or Ubuntu based system) is now boring, easy, and automated. I get to leverage the fact that the upstream developers put a ton of time and testing into packaging their software and it’s one more chore I don’t have to do.
For the Red Hat based distributions, it’d only change a little to look more like 👇 for updates.
1
2
3
4
5
6
7
8
dnf-updates:
runs-on: (target tag)
steps:
- name: Update using dnf (or yum)
shell: bash
run: |
sudo dnf clean all
sudo dnf update -y
Let’s handle failures
It isn’t much harder to notify on failure. If any of the steps above fail, this will create an issue in the repo that controls these runners. You can of course create more complex logic like assign it to a team, add comments, and more (docs to do all that).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
create-failure-issue:
name: Create an issue on failure of any step to investigate
runs-on: ubuntu-latest # use GitHub hosted runners
if: ${{ failure() }}
permissions:
contents: read
issues: write
steps:
- name: Create failure issue
shell: bash
run: |
gh issue create -R some-natalie/some-natalie \
--title "Update on pihole failed" \
--body "Please investigate!"
Handy tasks to include
🧰 Don’t be limited to operating system updates. Throwing manual tasks into cron is one of the oldest tools in the sysadmin toolbox. Here’s a couple more examples:
Clearing the local Docker cache of images not in use is handy from time to time. This is particularly helpful on self-hosted Dependabot runners, as those tend to be VMs and also tend to be large containers that change on each GHES upgrade.4
1
2
3
- name: Clear the docker cache
shell: bash
run: docker system prune -a
I run a local DNS and DHCP server using Pi-hole for blocking ads across my home network. Keeping that up to date has one more step to check for new software or blocklists.
1
2
3
4
5
- name: Update pihole
shell: bash
run: |
sudo pihole -up
sudo pihole -g
Strengths
It’s easy, automated, and audited. No one has to SSH into machines and do things manually like a barbarian.
It’s one less tool to manage (if you’re already needing to self-host your compute).
It can notify on failure (also likely one less tool to manage).
And it’s entirely undramatic. 🥱
Here’s an example of boring updates and reboots happening without anyone caring or noticing for weeks:
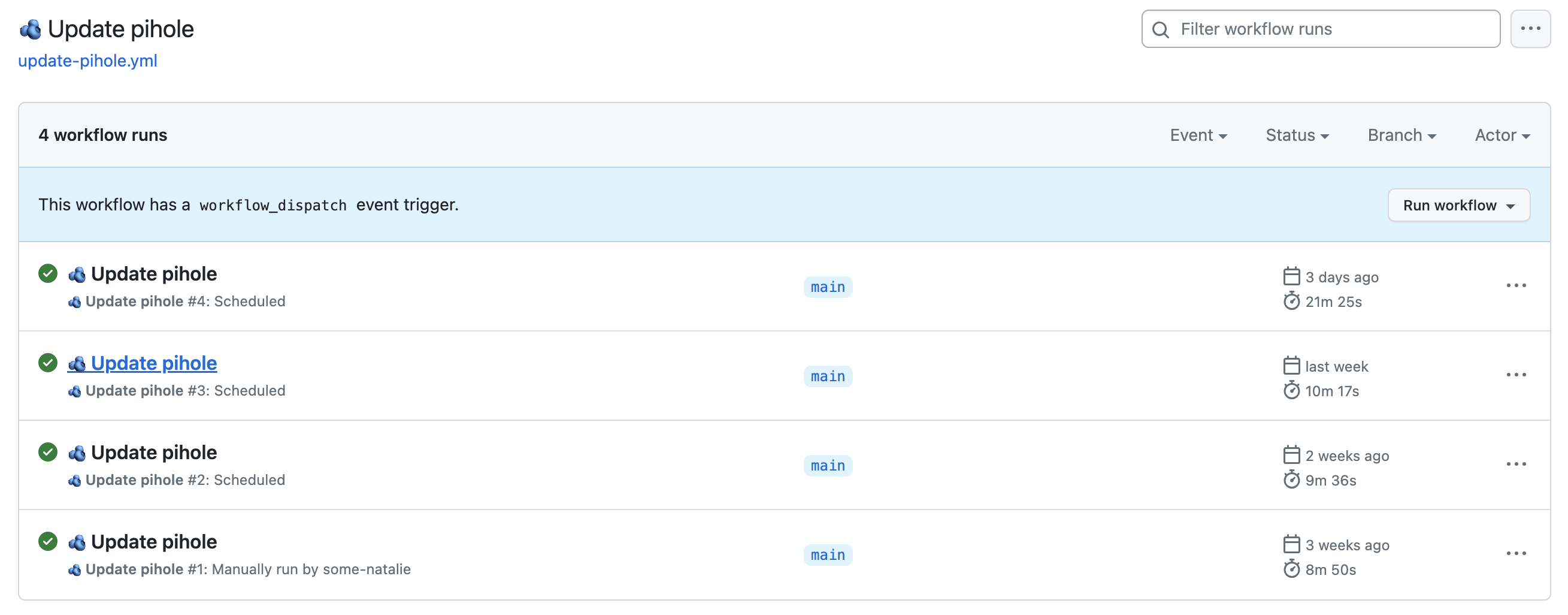
Limitations

🎃 Not as spooky as we thought for Friday the 13th, right? You can even continue to gate updates through your internal repo mirrors, just … keep those up to date too, please. 🥺
Obviously, this is for persistent VMs or bare metal compute only. Ephemeral (usually container-based) runners don’t have any of these concerns, as updates happen on building a new image.
There’s also none of the enterprise fleet management niceness that I’m used to - no rollbacks, phased deployments, state management, etc. I wouldn’t recommend using this at large scale, but this has worked fabulously for a home lab. It would work quite well for labs, most build farms, and other “easy to overlook” environments in the enterprise too.
Disclosure
I work at GitHub as a solutions engineer at the time of writing this. All opinions are my own.
Footnotes
-
I still don’t know why this is, but my guess is that different teams are responsible for the dev/test/production environments versus build servers to put things into that promotion path. If you have a better idea, lemme know? ↩
-
Particular needs around complex software should be met with investing in robust regression and acceptance tests, observability, and deployment logic for the applications on top rather than living in fear of the next inevitable CVE. This requires some level of engineering discipline to maintain the application, the dependencies, and such … but it also prevents the sheer terror of rebooting a machine that has 1000+ days of uptime. If the thought of running
yum update -y && rebooton a Friday scares you, 💓 fix that 💓 ↩ -
This should work equally well for any other bare metal or VM-based compute in other CI systems - GitLab, Azure DevOps, etc., all have the ability to schedule jobs. I have used this approach with Jenkins in a prior job and it’s quite serviceable. The code for these jobs is all public in GitHub, so continuing to minimize tool sprawl for things Not My Job is ideal. ↩
-
More about that in the official docs or if you’re using Red Hat (or derivative) VMs instead here - Dependabot on Red Hat Enterprise Linux using Docker. ↩