Kubernetes on Raspberry Pi computers

A modest abundance of Raspberry Pi computers means I simply must build a little Kubernetes cluster. Having lost my near-infinite supply of Azure credits, it’ll be a nice return to how I got started to run bare metal clusters.
The goals for this are straightforward. It must be
- Easy to reset when I mess things up
- Sized large enough to test things reasonably quickly
- Quiet and child-resistant, as I don’t have dedicated “home lab” space
- Maintain itself automatically (for the most part, anyways)
To that end, the stack I chose is Raspbian OS Lite for the node operating system, k3s for lightweight container orchestration, and repurposed automation using GitHub Actions for maintenance.
Hardware
I used four Raspberry Pi 5 computers with 8 GB of RAM each, adding for each one
- A cheap 128 GB SD card
- Passively cooled case (this one to be exact)
- Quality power supply
To network them together, I used an inexpensive 5-port gigabit unmanaged switch. I made the patch cables to length as I didn’t have a bunch of short ones on hand.
 a temporarily (probably permanently) wiring mess of ethernet and power for small computers
a temporarily (probably permanently) wiring mess of ethernet and power for small computers
The passively cooled case is surprisingly effective, perhaps because these are not under constant heavy load. The reported temperature using vcgencmd measure_temp hovers around 42-48°C, depending on load and ambient temperature. This is well below the threshold for thermal throttling, much less a concern for stability or longevity. Eventually, I’d like to add this metric to a small observability stack for it … but that’s a project for another day.
Node setup
Format each SD card with the Raspberry Pi imager , choosing the “lite” distribution option. It doesn’t need all the extra software in the regular image. The imager will prompt you for some information. I added the SSH public key I’ll need, set the hostname (eg, cluster-1) for each, and that was about it. This part of the process has gotten delightfully simple over the years - no remembering how to use dd and then mount it to edit the appropriate files to do the same tasks.
My network doesn’t rely on static IP addresses, further enabling the “easy to nuke it” goal. The Pi-hole on my network is configured for static DHCP leases. When given the MAC address of a network card, it will always be assigned the same IP address. This means that if I want to play around with a new operating system or need to replace the SD card, no configuration is needed for it to get the exact same IP address as before.
Do the boring system updates and install a few extra things.
1
2
3
4
5
6
7
8
9
10
11
# boring system updates
sudo apt update
sudo apt dist-upgrade -y
# install Helm, needed for what I want to use the cluster for
sudo apt install git -y
curl https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 | bash
# cleanup and reboot
sudo apt autoremove -y
sudo reboot
By default, the Raspberry Pi OS doesn’t ship with the memory cgroup enabled. This saves a small amount of overhead. It makes sense to conserve resources in an embedded system instead of defaulting to support a smaller use case.
We’ll need to enable this for our container runtime to work. The boot commands are read from a file at boot, so it’s a simple edit to add them and reboot.
1
2
3
4
5
sudo vim /boot/firmware/cmdline.txt
# append the following two entries to the file in-line
# cgroup_memory=1
# cgroup_enable=memory
Install and configure k3s
For a single control plane, plus n workers, it’s as simple as following the directions from k3s.io . Install it on the control plane, then get the token needed to join the cluster for each worker node. The only weird note is you may need to use an IP address for the K3S_URL if DNS isn’t resolving correctly on your local network.
1
2
3
4
5
6
# from the control-plane
curl -sfL https://get.k3s.io | sh -
sudo cat /var/lib/rancher/k3s/server/node-token
# from the workers
curl -sfL https://get.k3s.io | K3S_URL=https://cluster-1.contoso.com:6443 K3S_TOKEN=myreallylongtoken sh -
From the control plane, it may be helpful to move the administrator’s Kubernetes configuration file to a location that the regular user can access. For a “real world use case”, this is a bad idea to let regular users have privileged access. For a home lab that’s also running sudo without a password, it’s not a huge additional threat.
1
2
3
4
5
sudo cp /etc/rancher/k3s/k3s.yaml ~/.kube/config
sudo chown $USER ~/.kube/config
chmod 600 ~/.kube/config
export KUBECONFIG=~/.kube/config
echo "export KUBECONFIG=~/.kube/config" >> .bashrc
If all’s working as expected, you should see all the nodes Ready to go! 🎉
1
2
3
4
5
6
pi@cluster-1:~ $ kubectl get nodes
NAME STATUS ROLES AGE VERSION
cluster-1 Ready control-plane,master 27m v1.31.4+k3s1
cluster-2 Ready <none> 25m v1.31.4+k3s1
cluster-3 Ready <none> 24m v1.31.4+k3s1
cluster-4 Ready <none> 24m v1.31.4+k3s1
Make it update itself
Without the magic of a cloud provider scaling and updating the pool of nodes, the process of removing workloads from a node to reboot it without disrupting the cluster is straightforward. While running a high availability bare metal cluster, the process looked like this:
- Drain the node to evict running workloads, which will also cordon it to prevent new workloads from starting.
- If it’s a persistent node, update and reboot it, then wait for it to rejoin the cluster.
- If it’s an ephemeral node, discard it and start a new one, joining it to the cluster.
- Uncordon the node if needed to allow it to take on new jobs.
The process is similar for the control plane nodes as well. Once you account for the uptime/liveliness checks on each step, plus failure handling, it can get intricate depending on the stack used for automation. There is literally nothing in this cluster important enough to work this hard for. So … why not just update and reboot them all at once? 🥂
To do this, I reused another job to make GitHub Actions run all updates and reboot. As a CI orchestrator, it assumes that nodes are completely interchangeable within some grouping. For GitHub Actions, that grouping is called a “label”. Labels provide whether a node is a control plane or worker (or other category or fact about the system), but there’s no easy way to say “run this task on every worker with label”. This means that each computer needs a unique label, which we then use to tell GitHub to run this job on all of them using the built-in matrix logic. In practice, here’s what that looks like:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
updates:
name: Update the OS and reboot the machines
strategy:
matrix:
node: [cluster-1, cluster-2, cluster-3, cluster-4]
continue-on-error: true
runs-on: $
steps:
- name: Update the apt cache
shell: bash
run: |
sudo apt clean
sudo apt update
# more update steps, checks, and logic to run on each node
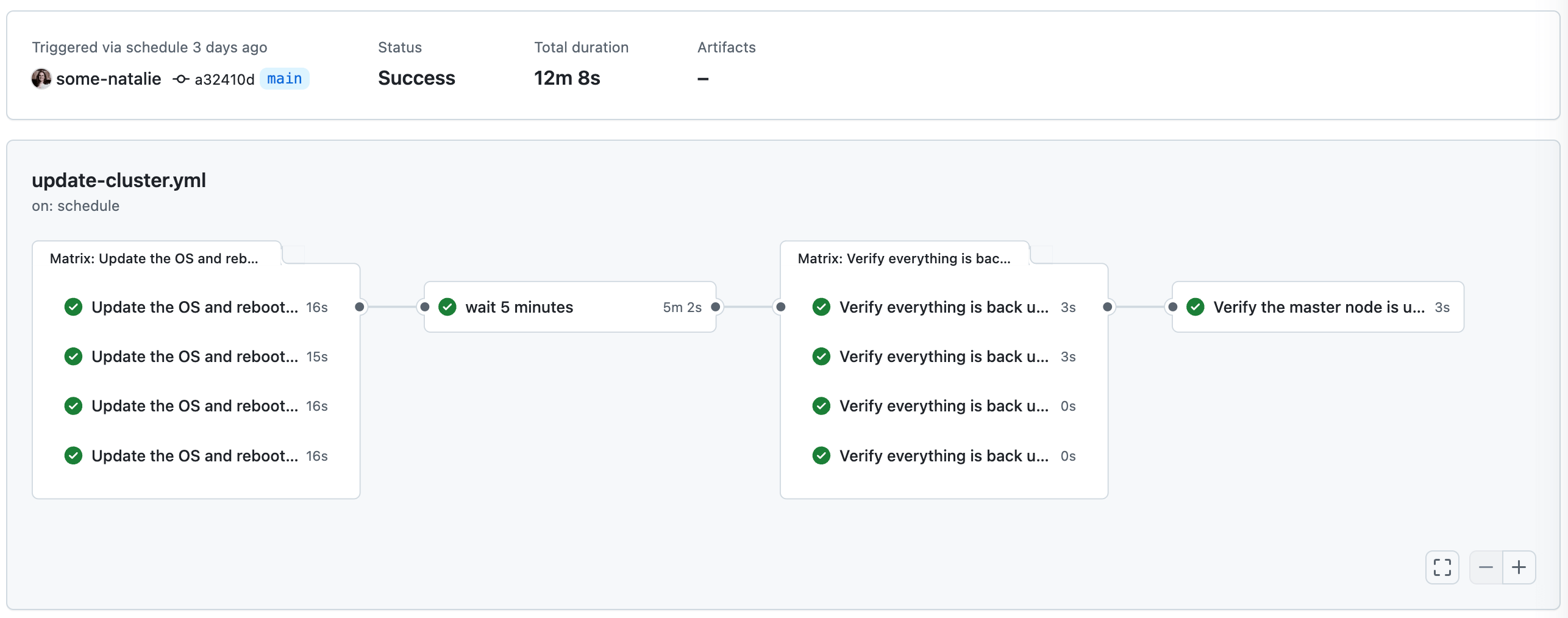
This has been chugging along without complaint for a few weeks now. While there is a way to assign runners labels with an API (docs ), it is both not available in actions-runner-controller and not helpful when the nodes are persistent. However, it would be handy to build some bespoke jobs around if needed.
Parting thoughts

I don’t believe this makes any sense for a “real business” use, but as a home lab it works nicely. It’s both easy to reset and mostly maintains itself. The hardware is plenty capable for experimentation. The software choices are less-than-ideal outside of small labs. GitHub Actions is forgiveably kludgey for using it at tasks it wasn’t designed to do, yet still works well at it. I’d used SaltStack and Puppet for similar maintenance tasks in the past, but neither of those spark enough joy to roll it out versus reuse something serviceable.
This is my first time using k3s over Kubernetes. It’ll be fun to explore the middle ground between picking literally every component and having all infrastructure abstracted from me. However … were it something I was responsible for, I’d use the managed Kubernetes service in my company’s cloud provider and call it a day. 🤷🏻♀️