What's a container, anyways?
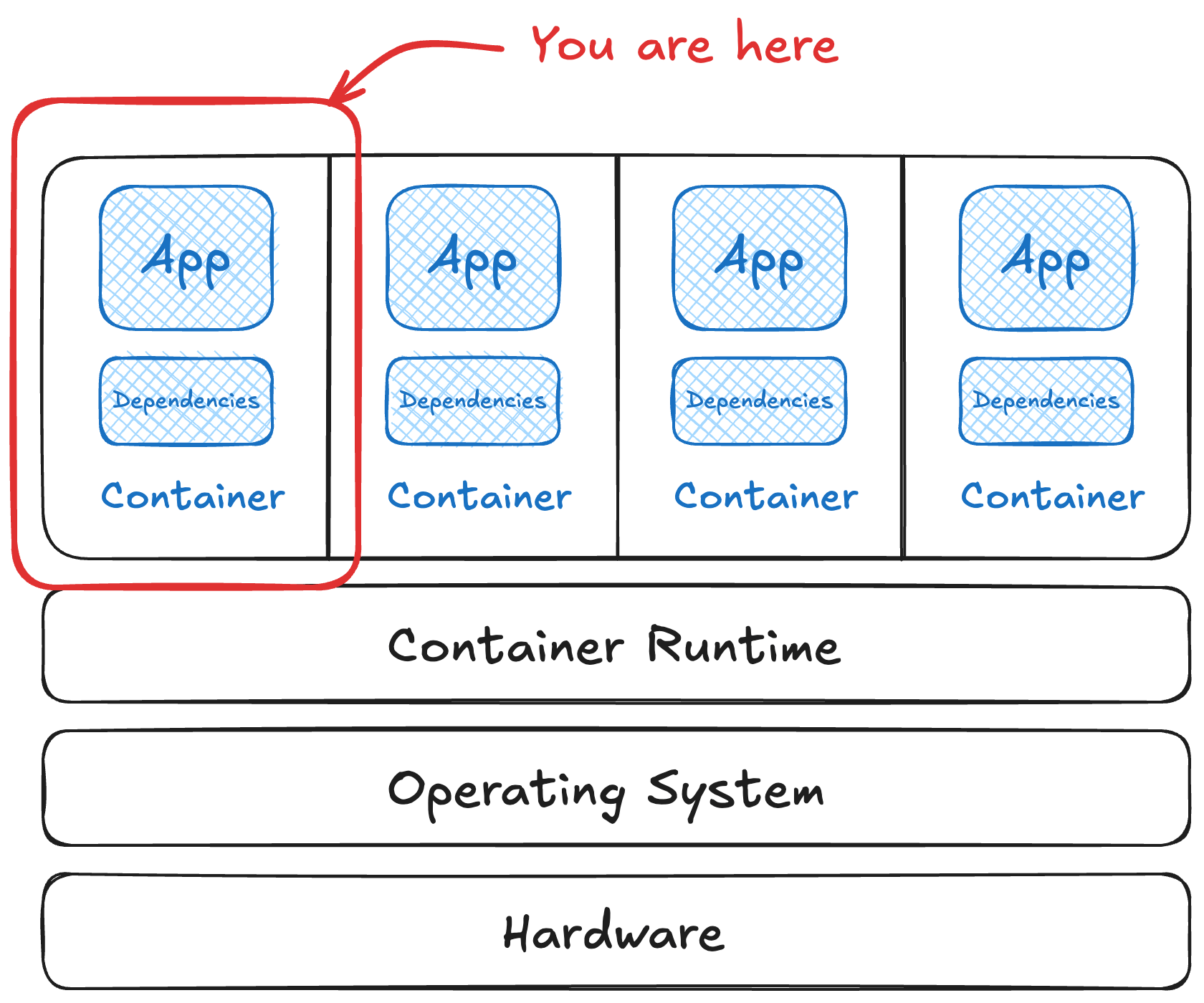
One of the most common (and sneaky) misconceptions I run across talking to folks using containers is what even is a container? It seems like we’re slinging around little appliances or little VMs. That’s how
- how dev teams build them (usually)
- how security teams scan them
- how we communicate risk about these systems
… but that’s not the case at all!
Let’s walk through a few basics before we get into the fun security parts.
This is part of a series put together from client-facing conversations, conference talks, workshops, and more over the past 10 years of asking folks to stop doing silly things in containers. Here’s the full series, assembled over Autumn 2025. 🍂
What is a container?
A container is a Linux process that carries along its own dependencies.
This makes it great for packaging software to run elsewhere. The original marketing success was “build once, run anywhere” for commercial tools1 years after this concept was used to build and distribute software.2 It took away all of the worrying about system dependencies, as it could rely on having exactly the versions needed. Underneath all the lovely wrappers like docker and user interfaces, a container is a collection of filesystem snapshots (tarballs) and structured information (JSON).
Build a container image
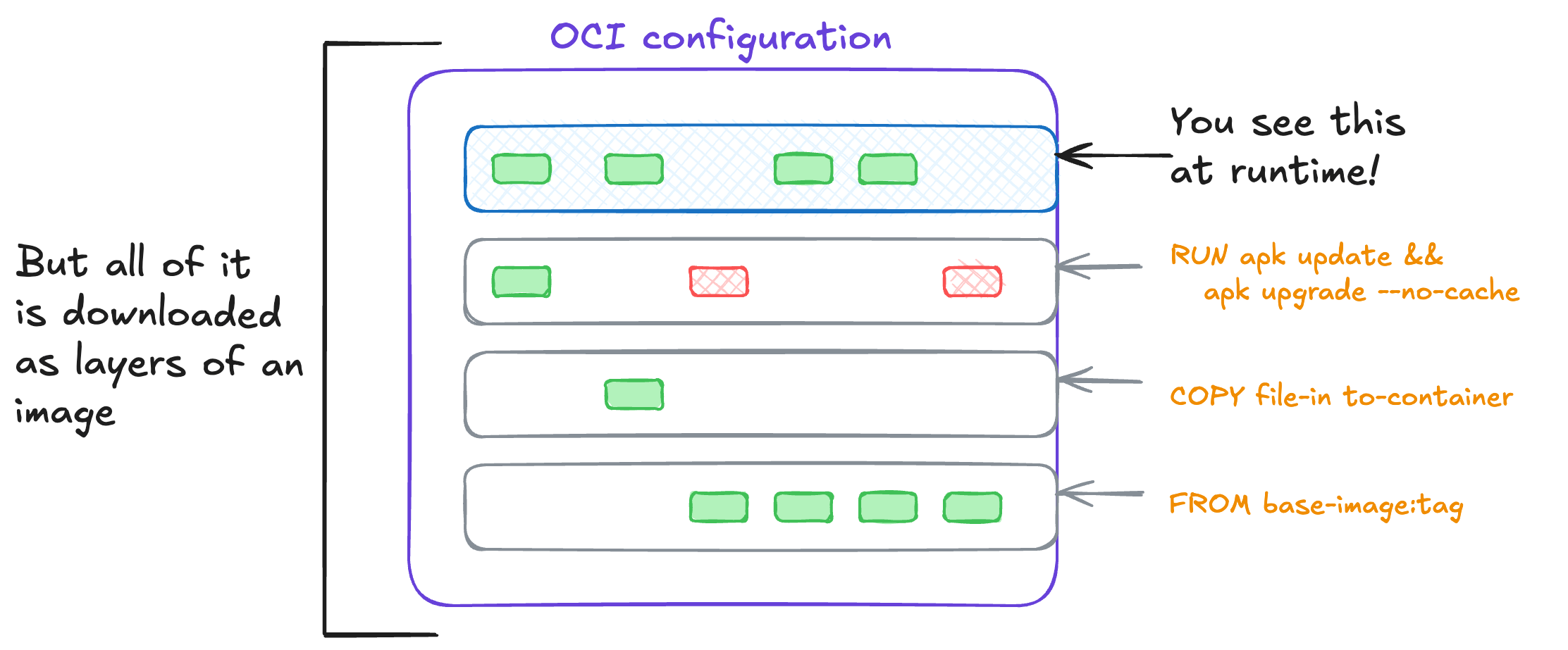
Building those filesystem snapshots is what happens at build time with each direction in your Dockerfile. Let’s look at an example:
1
2
3
FROM base-image:tag
COPY file-in to-container
RUN apk update && apk upgrade --no-cache
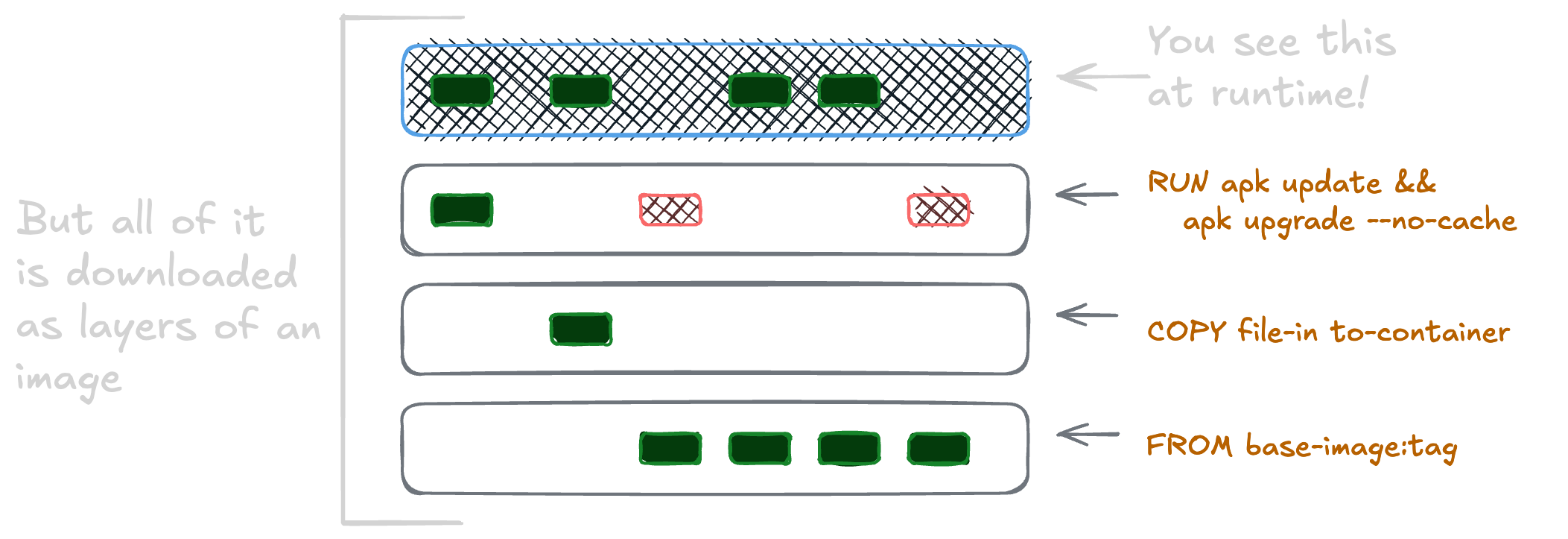
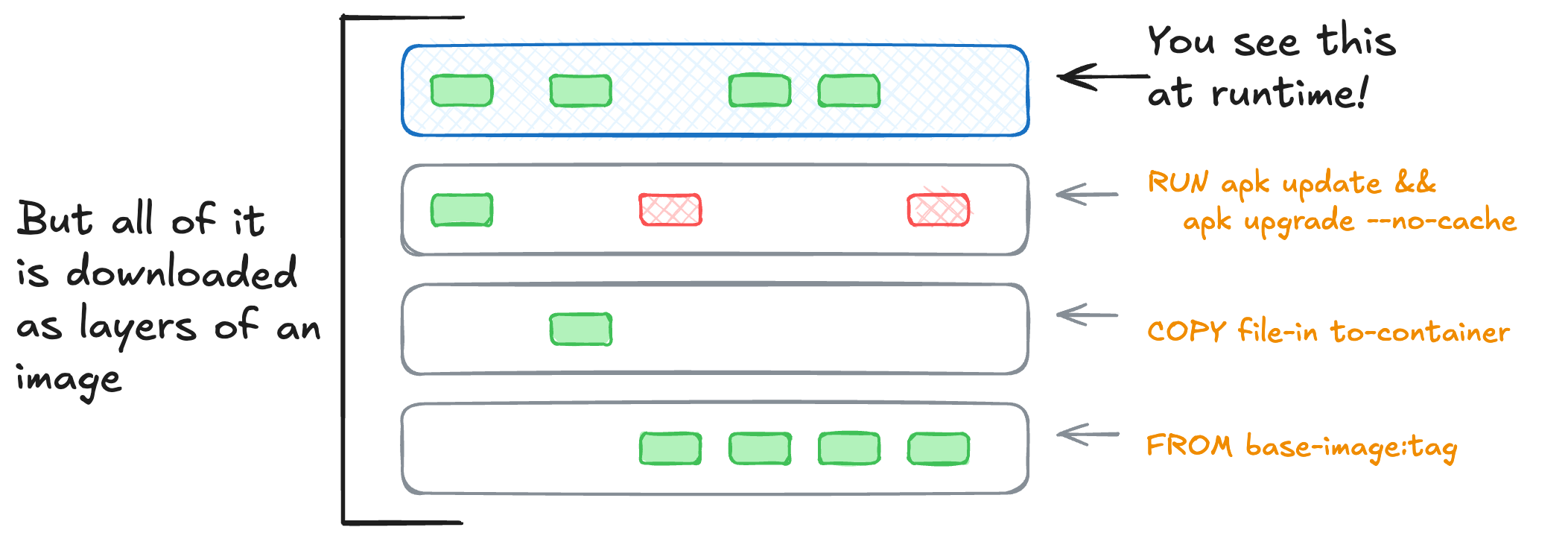
This file would create a set of file system snapshots that look like this:
 click to enlarge
click to enlarge
Each instruction creates a new layer, adding to the final image. These layers are each their own archive, which we’ll see in a moment.
This is nowhere near the only way to build a container image, but it’s the most common. The problem is my complex application build became a complex Dockerfile.

Containers promised simplicity. I should now be able to:
- Run as many copies as needed at the same time, in parallel, with no time needed to scale up/down
- Remove dependency hell across different processes on the same host
- Declare dependencies between services without hacky scripts or init systems
- Separate persistent states (data) from ephemeral workloads (tasks)
I could get rid of my existing configuration management tool (SCCM, Puppet, Chef, etc.), but the need for configuration management didn’t go away. Without deliberate engineering effort the “lift and shift” from my big makefiles or Jenkinsfiles or Packer build scripts …
🤦🏻♀️ became an equally complicated Dockerfile and container image. 🤦🏻♀️
Not using a technology for what it was meant for smells like security problems, doesn’t it? We’ll dig into these soon!
Moving a container around
1
2
3
4
5
6
7
8
~ ᐅ docker pull ghcr.io/some-natalie/some-natalie/secret-example:latest
latest: Pulling from some-natalie/some-natalie/secret-example
75e162d76c96: Pull complete # ⬅️ a layer
652eec629684: Pull complete # ⬅️ another layer
ccbf00a6e1a0: Pull complete # below, the digest! ⬇️
Digest: sha256:9fc7490905856ebd0731428f0b7c7a1906d095a2daf23a1fd160b58f0b38b143
Status: Downloaded newer image for ghcr.io/some-natalie/some-natalie/secret-example:latest
ghcr.io/some-natalie/some-natalie/secret-example:latest
While latest may change day-to-day, the sha256 digest cannot. It’ll always uniquely identify that combination of layers, their contents, and the configuration info for the image. To see the manifest file, we’ll look at the image manifest with docker manifest inspect for that image. The manifest is how a client knows which image layers and configuration to download.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
{
"schemaVersion": 2,
"mediaType": "application/vnd.docker.distribution.manifest.v2+json",
"config": {
"mediaType": "application/vnd.docker.container.image.v1+json",
"digest": "sha256:d688176b49d54a555e2baf2564f4d3bb589aa34666372bf3d00890a244004d02",
"size": 1424
},
"layers": [
{
"mediaType": "application/vnd.docker.image.rootfs.diff.tar.gzip",
"digest": "sha256:75e162d76c96dd343eab73f30015327ae2c71ece5cad2a40969933a8b3f89dbc",
"size": 5522209
},
{
"mediaType": "application/vnd.docker.image.rootfs.diff.tar.gzip",
"digest": "sha256:652eec62968485284a03eec733602e78ae728d5dc0bf6fcc7970e55c0dcb4848",
"size": 191
},
{
"mediaType": "application/vnd.docker.image.rootfs.diff.tar.gzip",
"digest": "sha256:ccbf00a6e1a0ff64cfaa5fc857932b4e22c4adee130ef5b64ecf8874650f9aad",
"size": 136
}
]
}
The "config" field shows us where the JSON is defined. Roughly, the contents look like this:
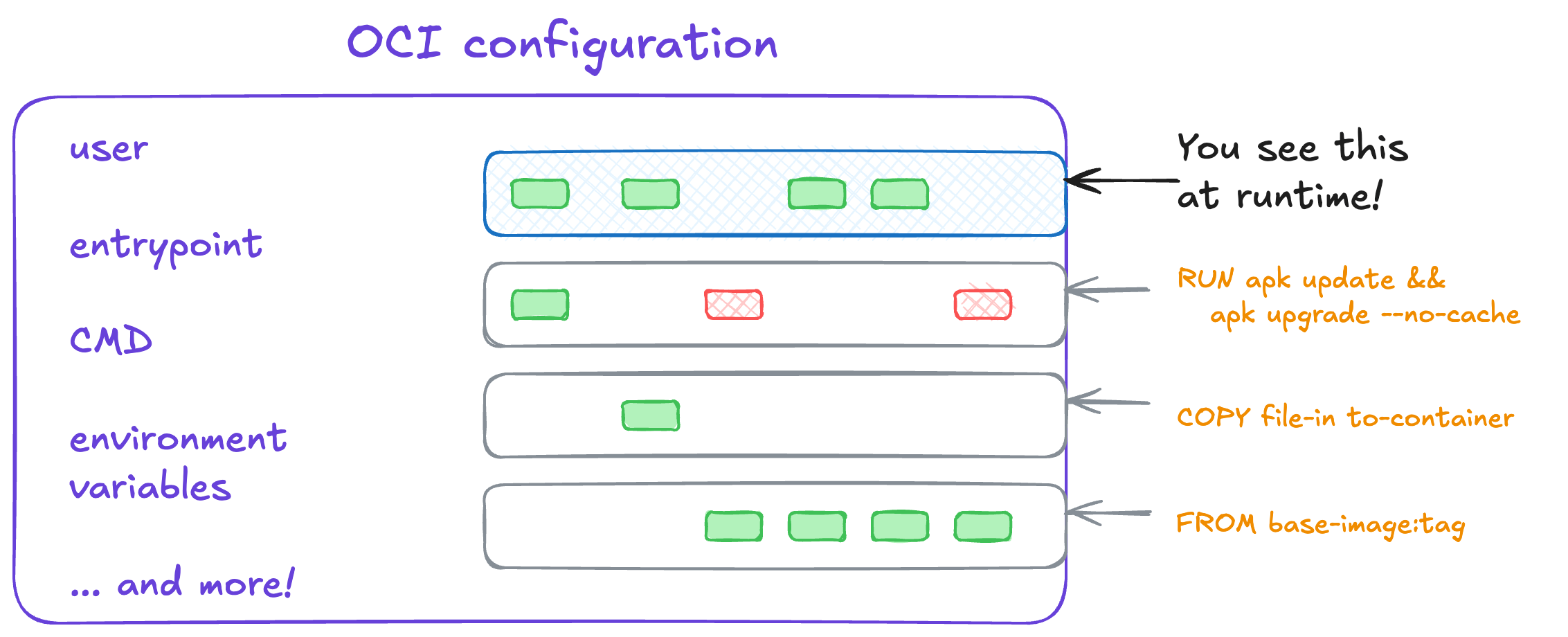
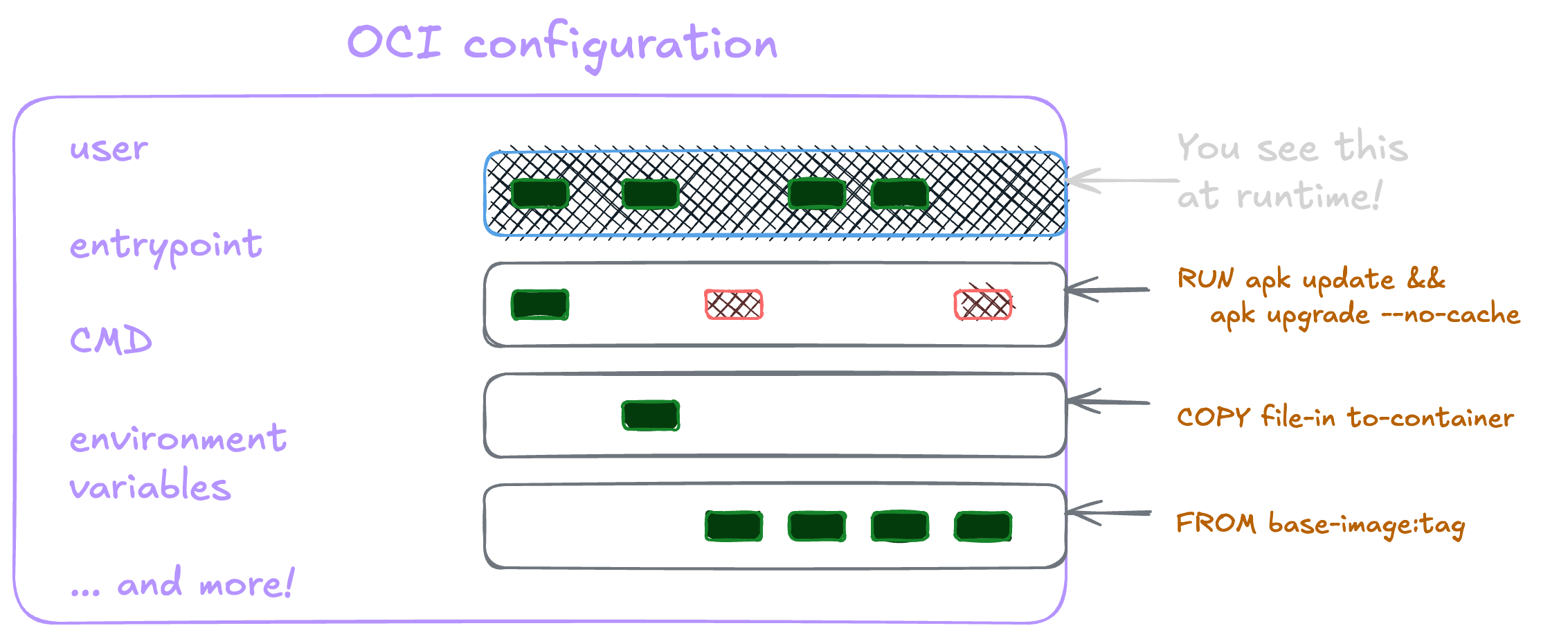 click to enlarge
click to enlarge
The full file has many more options than shown in the picture above. Some fields give other tools that use images information about it such as when it was created, what tools built the image, and more. Other fields are needed to know what to do with the contents, such as what user is needed and what process needs to start.
Sounds like there’s a lot that can go wrong here, even though
sha256collisions are functionally impractical to exploit. We’ll outline the threats to consider here soon!
Container isolation in a nutshell
Containers, like most Linux processes, carry very little “isolation” from each other by default. The host handles resource management and puts some guardrails in place to isolate it from other containers and processes it is running. These guardrails are a combination of Linux kernel features and tools in userland (outside of the kernel). While these all do something a little different, they each have a part to play in container security. Let’s dive in.
Seccomp
The lowest level of our container stack is the operating system on the host. These resources are accessed by any process in the operating system (a container or not) by system calls (syscalls ). These allow the process to interact with resources, like reading a file or writing to a network socket, and try to guarantee it plays nicely with everyone else sharing the same hardware. We could spend many hours talking about system calls, but this is all we need for today.3
The foundation we build on is the Linux kernel’s Secure Computing state, usually called seccomp . Introduced in the mid 2000’s, it has been critical to process security. It limits the system calls a process can make, allowing the OS to isolate processes better.
🪤 I think of seccomp as a mouse trap for processes - a process can enter, but the only way out is death. While alive, it can read and write to files it has open. It can exit nicely (exit()) and return a signal on whether it was successful or not (sigreturn()). If the process tries to do anything beyond what it’s been allowed to by making a forbidden syscall, the kernel kills the process or logs the event (if not enforcing).
Moving up a level, while there are hundreds of system calls in Linux, your containerized application likely only needs a much smaller set of them. Many container runtimes limit these by publishing and using a default seccomp profile. The Docker engine publishes good documentation on their seccomp profile as an example.
Namespaces
Moving up a level in the kernel are namespaces . These define what a process is allowed to see. It’s how the system shows resources to a process, but they can appear dedicated for isolation.4 There are eight at present. At a high level:
-
cgroup- control groups, more on this in a moment -
ipc- inter-process communication, does exactly what it sounds like -
mount- controls mount points, enabling filesystem reads and writes -
network- a virtual network stack, enabling network communication -
process- process IDs -
time- system time -
uts- allows a process to know the hostname (stands for Unix Time-Sharing) -
user- user IDs and mapping them between host and process
Here’s a quick example of passing one namespace, the hostname, into a container. Note how the --uts=host flag changes to allow the host’s name in the container. Without it, the container uses a random container identifier as its’ hostname.
1
2
3
4
5
6
7
8
9
10
11
user@demo:~$ docker run -it --uts=host ubuntu:jammy bash
root@demo:/# exit
exit
user@demo:~$ docker run -it ubuntu:jammy bash
root@21f946f01f9c:/# exit
exit
user@demo:~$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
21f946f01f9c ubuntu:jammy "bash" 4 seconds ago Up 4 seconds jolly_galois
Minimizing what’s available to a process minimizes our attack surface. Some of these are likely not to provide much foothold, like system time. Others are much more impactful. Let’s look more at one of these in particular, control groups.
Control groups (cgroups)
Control groups are similar to a weird file system5. They define what the process is allowed to have. This is how the kernel knows to limit a process to only have so much memory or CPU time.
Ideally, we humans aren’t going to interact with performance-tuning or rate-limiting individual applications. There are usually sensible defaults in place, but you can restrict them further if you’d like. If this is set incorrectly or limited, it provides an easier path to consuming all the resources on a system. This is also how a container runtime and orchestrator can predict resource usage on a machine. Here’s an example of setting a memory and CPU limit on a container:
1
2
3
4
docker run -it \
--cpus="1.5" \
--memory="1g" \
ubuntu:jammy bash
Since this is a filesystem (usually mounted at /sys/fs/cgroup), escaping our container could allow writing or changing these to perform a denial of service attack. The underlying host features we talked about so far are how our container runtime knows to give this container these resources and constraints. Now let’s talk about permissions to do naughty things!
Capabilities

🧚🏻♀️ Once upon a time, one was either an all-capable administrator (root) or a plebeian with no special powers (user). That binary all-or-nothing approach of “root or not-root” has been replaced by capabilities . These define what a process is allowed to do.
Capabilities allow users to selectively escalate processes with scoped permissions such as bind a service to a port below 1024 (CAP_NET_BIND_SERVICE) or read the kernel’s audit log (CAP_AUDIT_READ). There are about 40 unique capabilities, which is much more than can be covered today.
Granting minimal permissions to each part of your containerized application is tricky. It requires developers to understand deeply what the app needs to do and how that translates to kernel capabilities. It’s tempting to just “give it everything” and move on, which is why we’ll talk more about CAP_SYS_ADMIN in our demo.
OverlayFS
These processes use overlayfs , a stacking filesystem that containers use. It’s best summarized by the commit message adding it to the kernel:
Overlayfs allows one, usually read-write, directory tree to be overlaid onto another, read-only directory tree. All modifications go to the upper, writable layer. This type of mechanism is most often used for live CDs but there is a wide variety of other uses.
This is how the container process can both carry its dependencies with it and not interfere with other processes’ files on the host. In practice, they look a lot like this:
 a drawn diagram of overlayfs
a drawn diagram of overlayfs
You can read more about overlay files in the kernel documentation or in Julia Evan’s lovely zine on overlayfs . Ideally, things you don’t want a container to write to are read-only on the host, and the container can’t write to them. That’s not always how it’s been configured though.
Mandatory access control (MAC)
Lastly, no container security talk would be complete without mentioning some host-based mandatory access control (MAC) system. The most common ones are AppArmor or SELinux . These act as watchdogs to ensure each process (container or not) is only touching resources it’s allowed to based on the user, their role, and the files/processes/tasks that are attempted.6

😩 The reason I bring this up is that it’s common to disable these.
It’s often the top-rated answer on StackOverflow or the first “fix” in a blog post that ranks high in search results. It is always a bad idea to disable these, as it’s a critical layer of security that can prevent a container from doing things it shouldn’t be doing. So naturally, we’ll be disabling these for our demo!
And this relates to security how?
Understanding the restraints the Linux kernel puts on a process and how they work is critical to understanding how they fail or can be misconfigured. This is how you gain a foothold and move around past where you’re supposed to be.
If it can be hard to understand, it's likely to be easy to do insecurely.
There continues to be astonishing amounts of work to improve this by default. Sensible defaults are probably the most powerful tool in secure systems. As an example, it used to be that Docker always ran as a service (daemon) using the root user. This is no longer the case and rootless Docker is now the suggested default. Other container runtimes, such as Podman , don’t use a daemon at all. Even more runtimes, like Kata containers aren’t actually container runtimes at all. Instead, they provide a set of workarounds to run containers inside dedicated micro virtual machines. We won’t talk about these VMs-as-runtimes much at all today, but they’re getting easier to use and more common now as well.
Up next: Host risks and other shenanigans (back to the summary)
Workshop: Back to the index.
Footnotes
-
The company was Docker, but not really the one we see today. Wikipedia has more details on this. ↩
-
Jails , both in
chrootfor filesystems in Linux and the concept w/i BSD, predate “containers”. Totally outside the scope of this. I’m going to assume you’re tall enough to ride this ride if you’re wanting to go down this path. :) ↩ -
System calls and application/kernel interfaces are way beyond the scope of this talk. If you want to learn more, I found this interactive Linux kernel diagram to be super helpful! The Linux Foundation also holds a training course on the Beginner’s Guide to Linux Kernel Development . ↩
-
We’re talking about a kernel namespace, which is a low-level concept that wraps system resources in such a way that they are shared but appear dedicated. Not at all confusing, but a “namespace” in Kubernetes is a high-level abstraction commonly used to divide a cluster’s resources among several applications. ↩
-
There’s two different versions to be aware of here, but the differences between them are way outside the scope of this talk. ↩
-
Red Hat published a coloring book on SELinux that remains one of the most delightful ways to understand how mandatory access control works. ↩