Using AI to open pull requests for dependency bumps

👻 It’s spooky season, so let’s do something a little scary … give AI a bit of power in one of my projects1. I have a chore that’s pure drudgery. It isn’t difficult or fun, just needs to be done more frequently than I want to do it. With some guardrails and good tests, giving to an AI agent seems reasonable.
I adore Dependabot , but there’s some things it just doesn’t do2. I need to bump dependencies inside of a Dockerfile. Not in the FROM line for another image, but git tags or other versions declared as arguments to install software at build time.
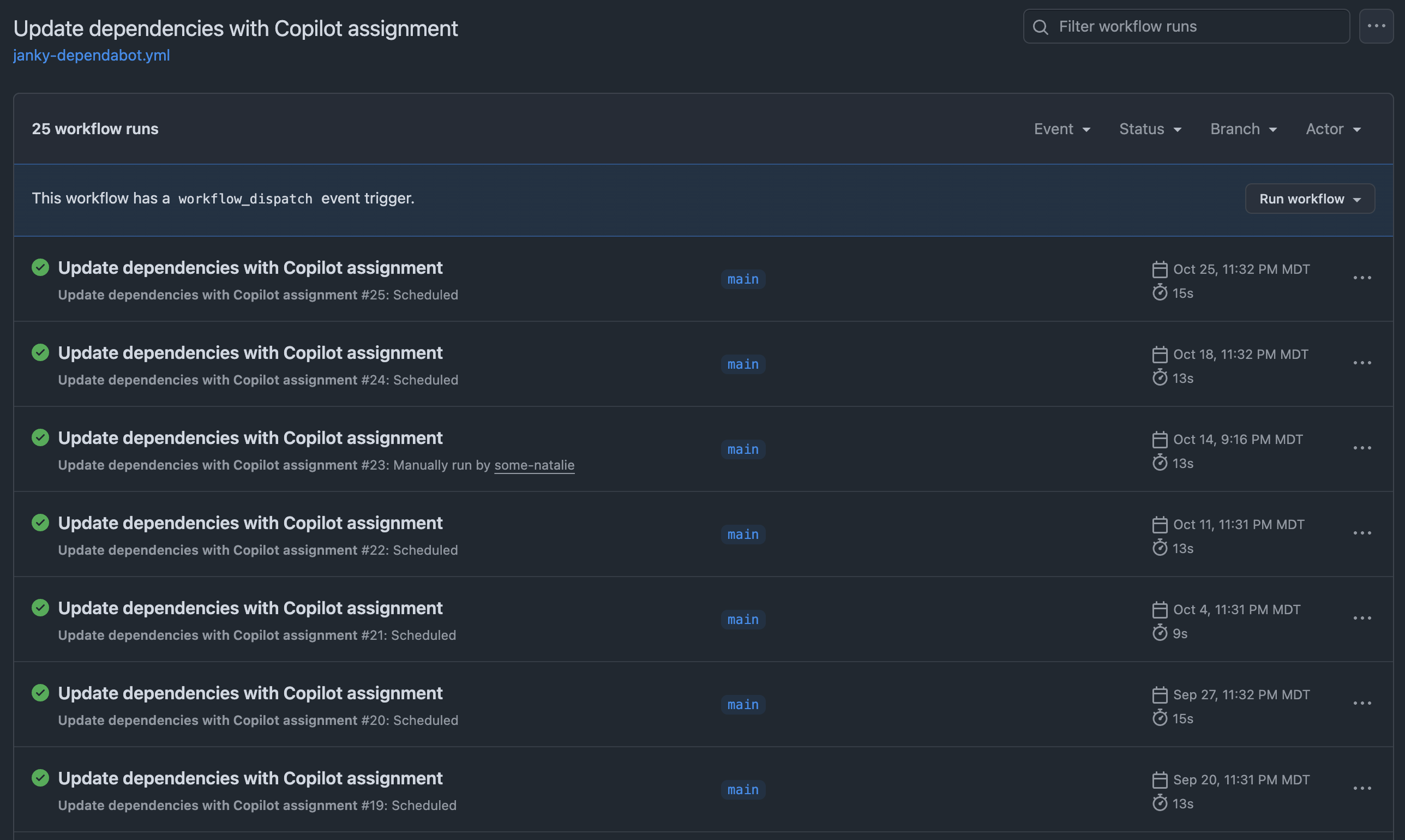
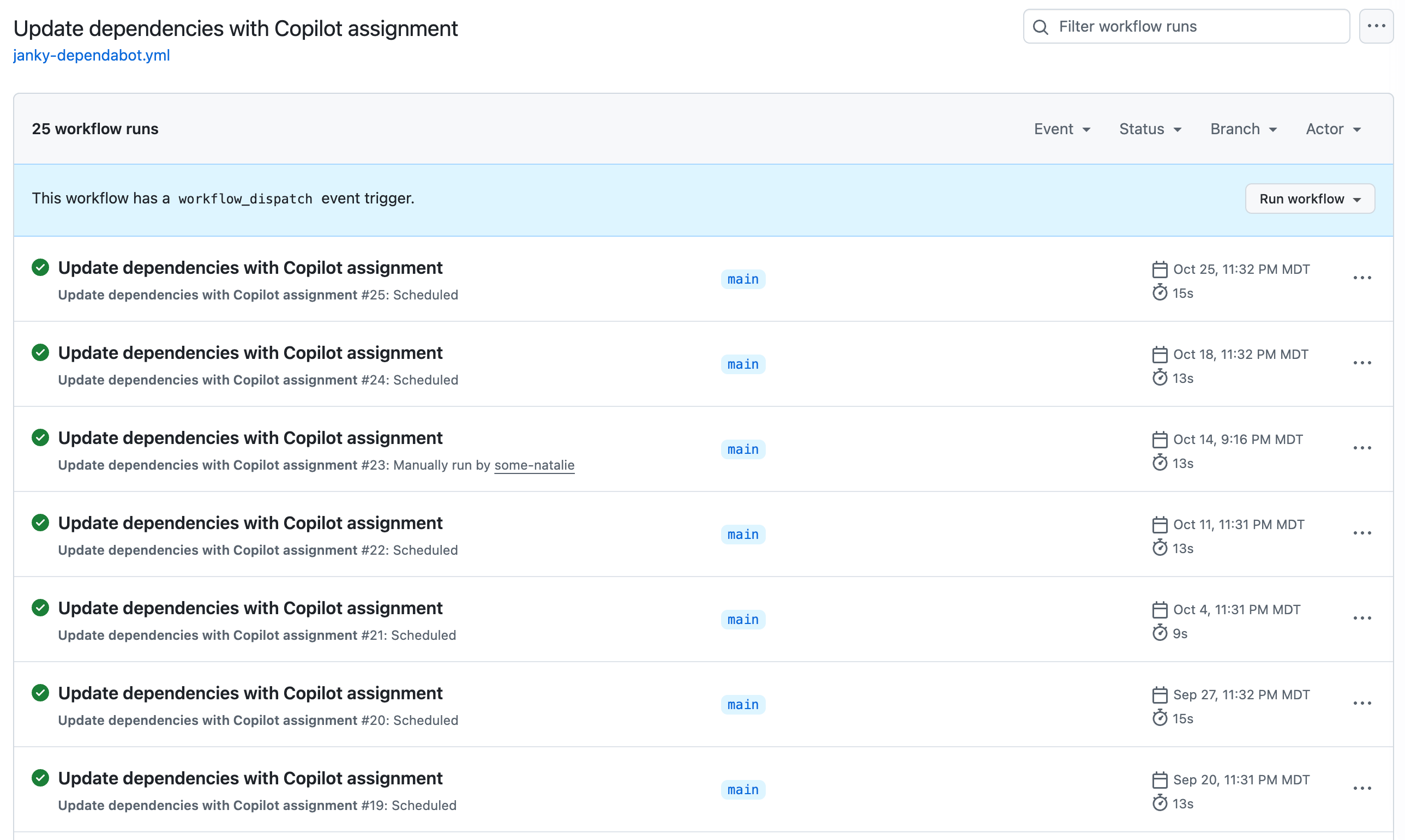
The end result of this is a recurring Actions workflow that opens an issue with directions on which dependencies to bump and where to look for version updates. The issue is assigned to the Copilot agent to send a PR with all the applicable version bumps.
Let’s make some AI-powered dependency updates to send bump PRs for the things Dependabot can’t do.
Create some directions for the AI agent to follow
This project has several Dockerfiles it builds, each with a different set of dependencies that use GitHub releases or semantically versioned artifacts. The versions of these are declared in each Dockerfile as an argument (ARG), allowing the versions inside to be pinned to a release.
Make an issue template with the information it’ll need to do the job.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
---
name: AI image dependency bumps
about: AI image dependency bumps
title: "AI image dependency bumps"
---
## Directions
Upstream projects that this project depends on.
- https://github.com/actions/runner is `ARG RUNNER_VERSION` and uses GitHub releases
- https://github.com/actions/runner-container-hooks is `ARG RUNNER_CONTAINER_HOOKS_VERSION` and uses GitHub releases
- https://github.com/Yelp/dumb-init is `ARG DUMB_INIT_VERSION` and uses GitHub releases
- https://docs.docker.com/compose/releases/release-notes/ is `ARG COMPOSE_VERSION` is Docker Compose and uses GitHub releases
- `ARG DOCKER_VERSION` is the community Docker engine and releases are semantically versioned. The list of versions can be found for the `docker-*` package at <https://download.docker.com/linux/static/stable/x86_64/>
For each of these projects, update the version in the Dockerfiles below _if and only if_ they appear in that file:
- images/rootless-ubuntu-jammy.Dockerfile
- images/rootless-ubuntu-numbat.Dockerfile
- images/ubi10.Dockerfile
- images/ubi9.Dockerfile
- images/ubi8.Dockerfile
- images/wolfi.Dockerfile
If there are updates, open a pull request and assign review to @some-natalie. Comment in that pull request that closing it will close the issue.
If there are no updates, close this issue.
With a many-to-many relationship between dependencies and containers to build, this becomes a chore quickly. After playing around with these directions, the most reliable path seems to be explicitly telling the AI agent:
- What to look for
- Where to look for it
- What to do with that info
Making any conditionals clear, like “do this if and only if”, seems to reduce garbage PRs that change nothing.
Create a secret for Actions to create issues
Make a fine-grained access token for the repository this lives in. It’ll need the ability to read and write actions, content (code), issues, and pull requests in that repository only.
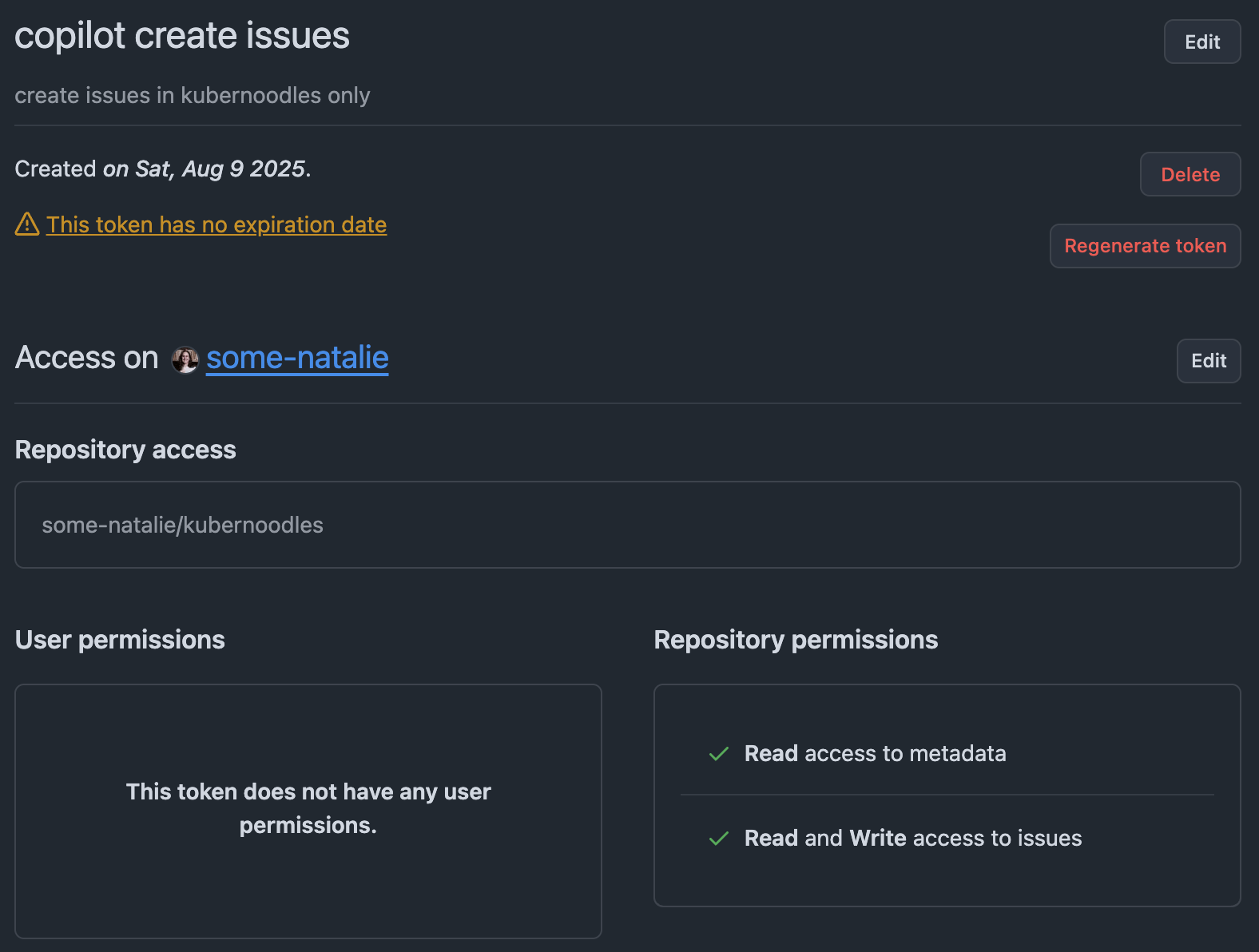
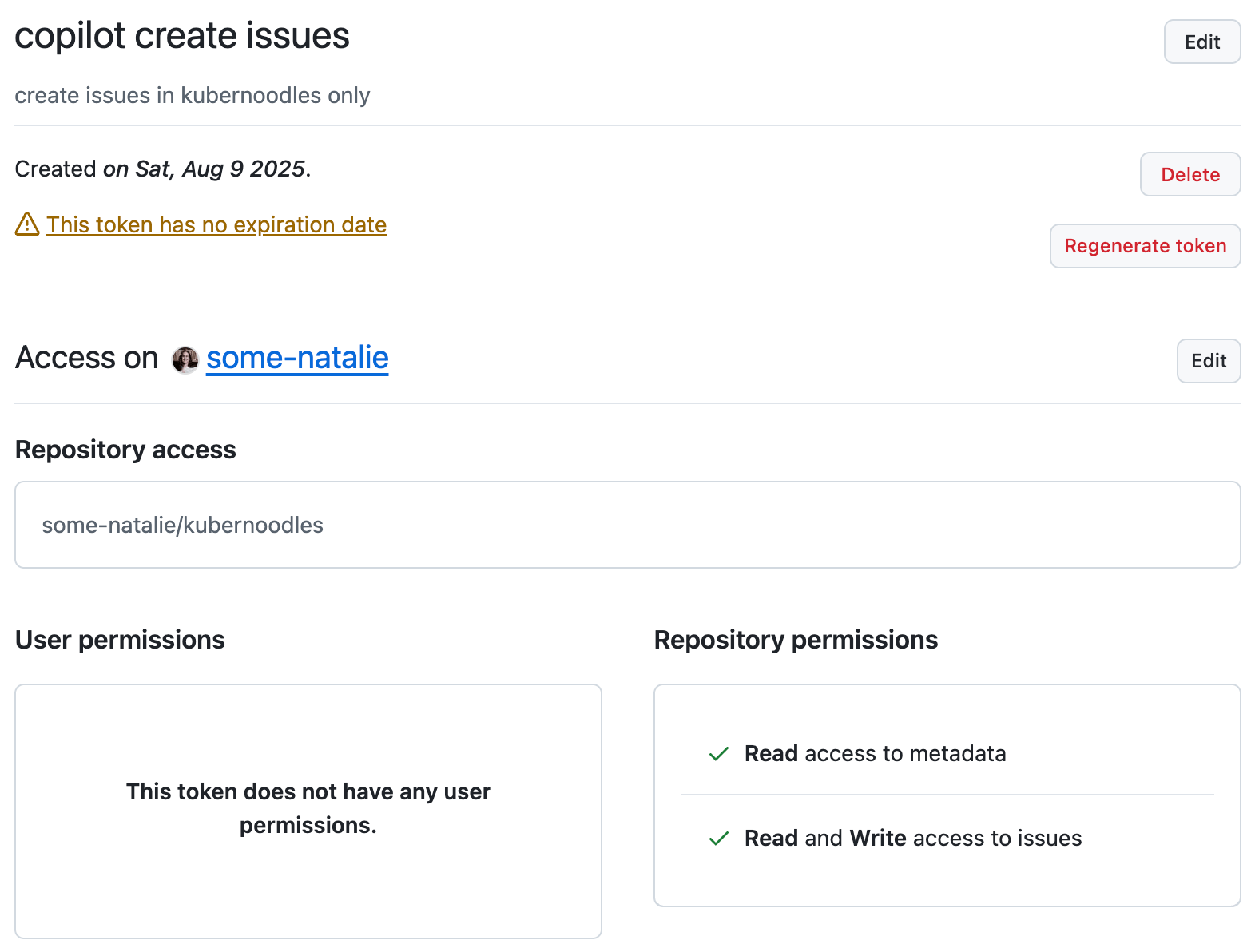 fine-grained access token example
fine-grained access token example
🙈 Yes, this is a long-lived secret. At least it’s very narrowly scoped to do one thing in one repo only. Being able to write issues to a public repo will be irritating to clean up, but not dangerous. One day, I’ll edit this to use octo-sts and OIDC instead … that day isn’t today.
Store this as a repository secret. I called it COPILOT_USER, used in the scripts below.
An Action to open an issue regularly
First, make a new workflow in ~/.github/workflows to run every so often. Weekly and on-demand work well for my project and my attention span, but this is simple to change to fit other project needs.
There is a lot of in-line shell scripting in YAML, which has been cleaned up to read. See the full file for what’s in use, the permissions it needs, etc.
1
2
3
4
5
6
name: 🤖 Update dependencies with Copilot assignment
on:
workflow_dispatch: # run on demand
schedule:
- cron: "27 5 * * 0" # run every Sunday at 5:27 AM UTC
Next, read the issue template using imjohnbo/extract-issue-template-fields . This stores the metadata from the YAML frontmatter and body in variables we can reference later on in the workflow.
1
2
3
4
5
6
7
8
9
10
11
steps:
- name: Checkout the repo
uses: actions/checkout@de0fac2e4500dabe0009e67214ff5f5447ce83dd # v6.0.2
- name: Get the issue fields from the template
uses: imjohnbo/extract-issue-template-fields@fcdd71b8add0dbd44221bcc368924a7722db96d2 # v1.0.3
id: extract
with:
path: .github/ISSUE_TEMPLATE/ai-update.md
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
Now for the tricky part - checking to see if this repository has GitHub Copilot enabled. If it does, get the bot ID for it. We’ll need that to assign an issue to it. Since this value differs by organization, using @copilot to assign issues is meaningless because that username can be many user IDs.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
# Get repository ID and check for Copilot
REPO_QUERY='query {
repository(owner: "${{ github.repository_owner }}", name: "kubernoodles") {
id
suggestedActors(capabilities: [CAN_BE_ASSIGNED], first: 100) {
nodes {
login
__typename
... on Bot {
id
}
... on User {
id
}
}
}
}
}'
RESPONSE=$(curl -X POST \
-H "Authorization: bearer ${{ secrets.COPILOT_USER }}" \
-H "Content-Type: application/json" \
--data-raw "{\"query\": \"$(echo $REPO_QUERY | tr -d '\n' | sed 's/"/\\"/g')\"}" \
https://api.github.com/graphql)
echo "GraphQL Response: $RESPONSE"
# Extract repository ID
REPO_ID=$(echo $RESPONSE | jq -r '.data.repository.id')
echo "REPO_ID=$REPO_ID" >> $GITHUB_OUTPUT
# Find Copilot bot ID
COPILOT_ID=$(echo $RESPONSE | jq -r '.data.repository.suggestedActors.nodes[] | select(.login == "copilot-swe-agent") | .id')
echo "COPILOT_ID=$COPILOT_ID" >> $GITHUB_OUTPUT
if [ "$COPILOT_ID" = "null" ] || [ -z "$COPILOT_ID" ]; then
echo "Copilot not found in suggested actors"
echo "COPILOT_ENABLED=false" >> $GITHUB_OUTPUT
else
echo "Copilot found with ID: $COPILOT_ID"
echo "COPILOT_ENABLED=true" >> $GITHUB_OUTPUT
fi
The script above will return whether or not Copilot is enabled (COPILOT_ENABLED). If it is, we’ll use the REPO_ID AND COPILOT_ID to open an issue later. If it isn’t, we’ll still open an issue later on as a fallback, but you’ll need to assign it to someone (or a different AI agent) manually.
Next, create an issue with all the info from the template and assign it to the correct bot.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
# Get current date for title
DATE=$(date +%Y-%m-%d)
# Log the repository ID and Copilot ID
echo "Repository ID: ${{ steps.copilot-check.outputs.REPO_ID }}"
echo "Copilot ID: ${{ steps.copilot-check.outputs.COPILOT_ID }}"
# Create the GraphQL mutation with proper JSON escaping
# First escape the body content for JSON
ESCAPED_BODY=$(echo '${{ steps.extract.outputs.body }}' | jq -Rs .)
ESCAPED_TITLE=$(echo '${{ steps.extract.outputs.title }}' | jq -Rs .)
# Build the JSON payload
JSON_PAYLOAD=$(jq -n \
--arg repoId "${{ steps.copilot-check.outputs.REPO_ID }}" \
--arg title "${{ steps.extract.outputs.title }} for $DATE" \
--argjson body "$ESCAPED_BODY" \
--arg copilotId "${{ steps.copilot-check.outputs.COPILOT_ID }}" \
'{
query: "mutation($repoId: ID!, $title: String!, $body: String!, $copilotId: ID!) { createIssue(input: { repositoryId: $repoId, title: $title, body: $body, assigneeIds: [$copilotId] }) { issue { id number title url assignees(first: 10) { nodes { login } } } } }",
variables: {
repoId: $repoId,
title: $title,
body: $body,
copilotId: $copilotId
}
}')
# Execute the mutation
RESPONSE=$(curl -X POST \
-H "Authorization: bearer ${{ secrets.COPILOT_USER }}" \
-H "Content-Type: application/json" \
-H "GraphQL-Features: issues_copilot_assignment_api_support" \
--data-raw "$JSON_PAYLOAD" \
https://api.github.com/graphql)
echo "Create issue response: $RESPONSE"
# Extract issue details
ISSUE_NUMBER=$(echo $RESPONSE | jq -r '.data.createIssue.issue.number')
ISSUE_URL=$(echo $RESPONSE | jq -r '.data.createIssue.issue.url')
echo "Created issue #$ISSUE_NUMBER: $ISSUE_URL"
echo "ISSUE_NUMBER=$ISSUE_NUMBER" >> $GITHUB_OUTPUT
echo "ISSUE_URL=$ISSUE_URL" >> $GITHUB_OUTPUT
There are other steps in the full workflow file fallback to create the issue if Copilot isn’t enabled, allowing you to use other AI tools perhaps. It also creates a run summary too, for visibility. Both of these steps got cut out for clarity here, but are in the file if helpful. ✂️
Rest while bots do the boring work
From here, it’s an automated task to open an issue and assign it to the robots to deal with.
Issue gets assigned to Copilot
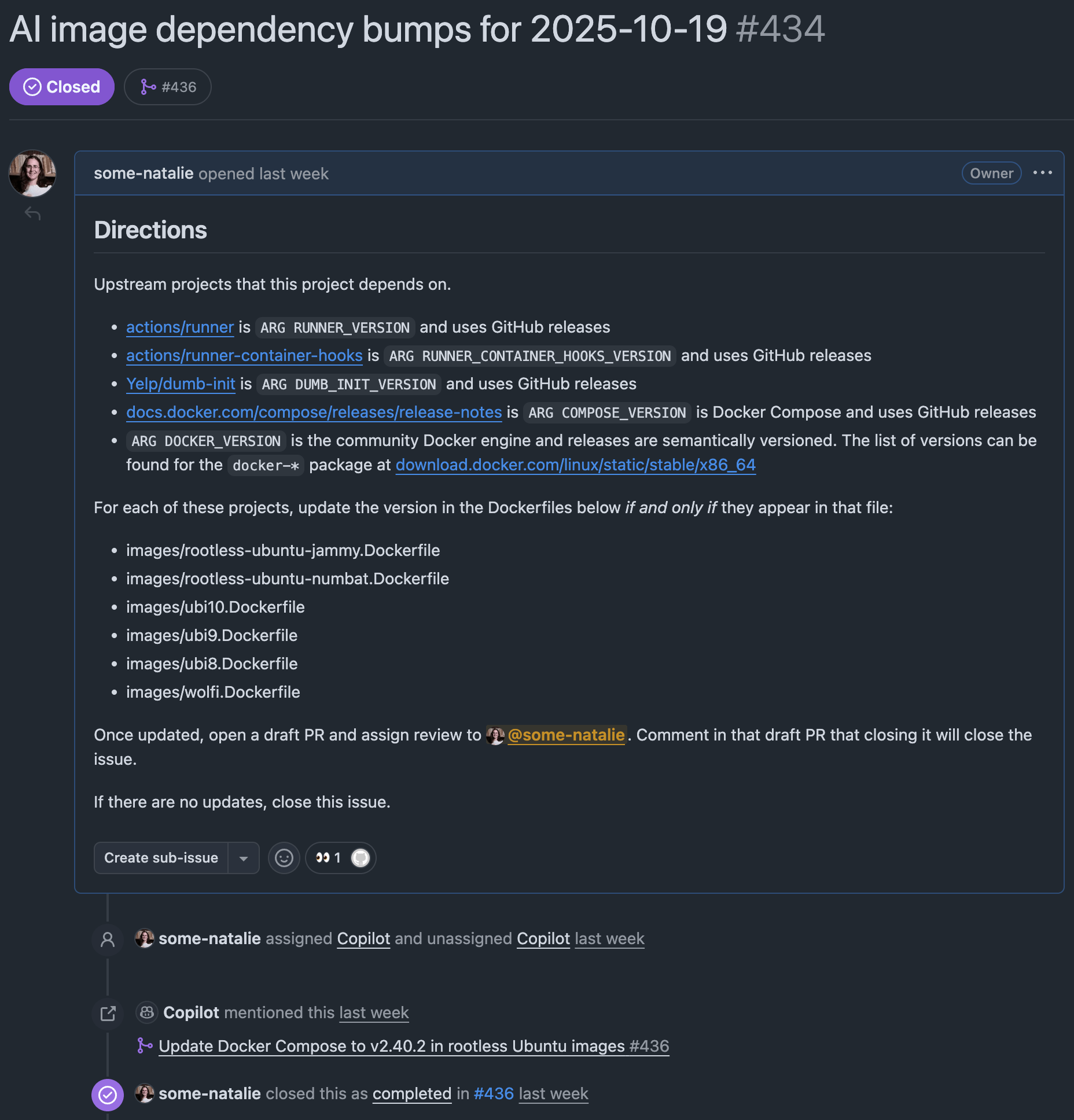
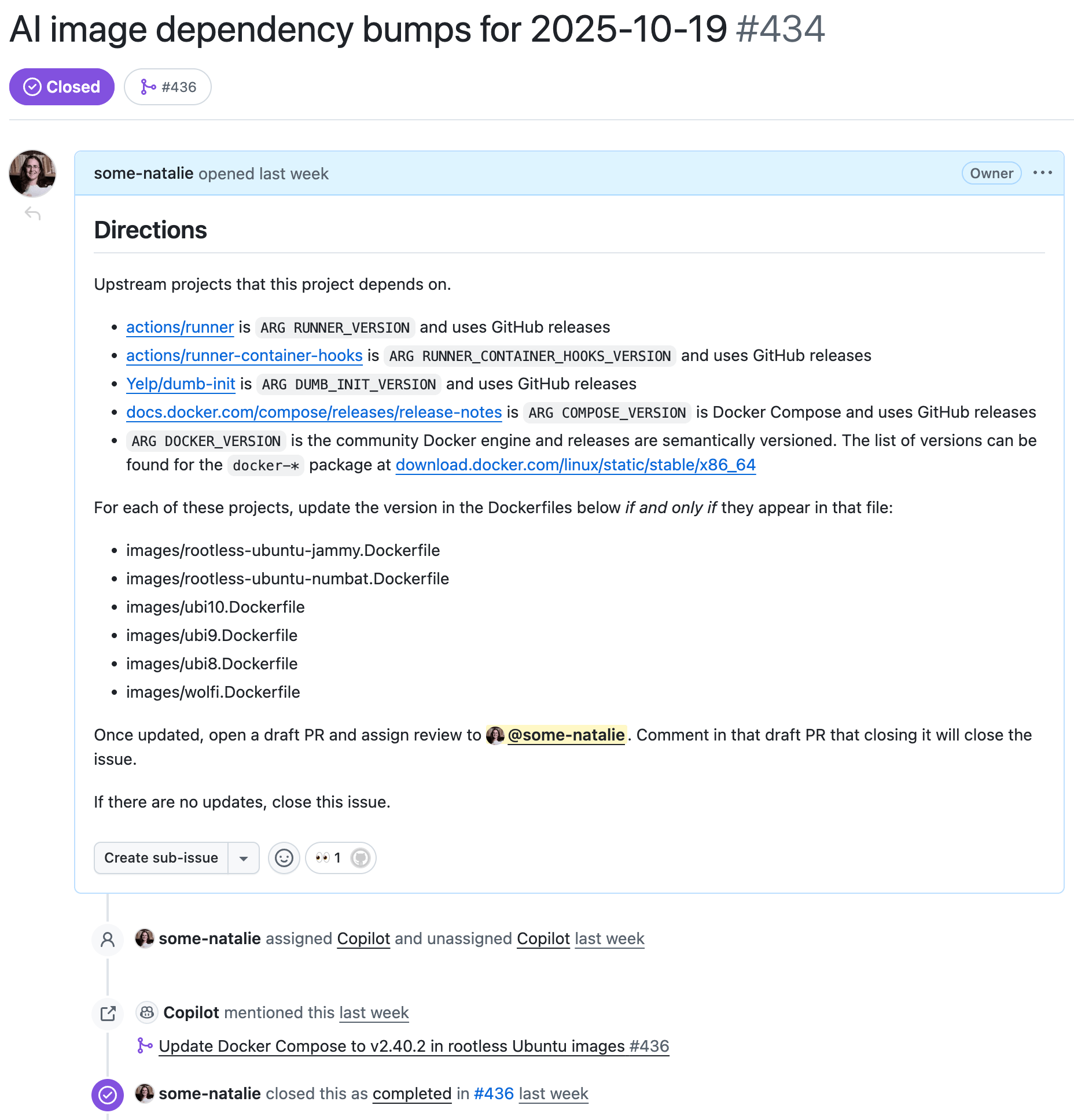 an example of the issue that’s opened and assigned 🪄 automagically 🪄
an example of the issue that’s opened and assigned 🪄 automagically 🪄
Copilot does things
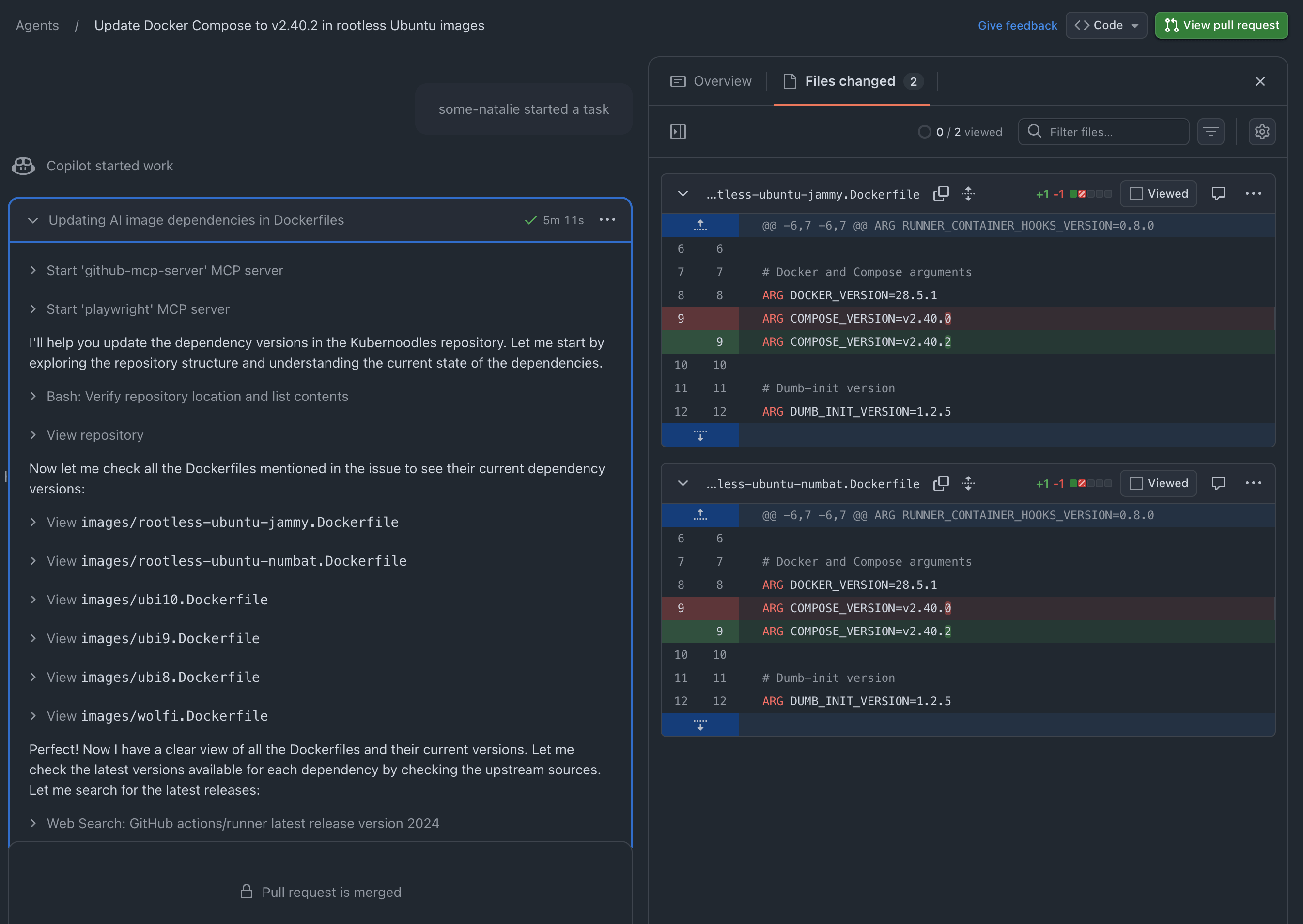
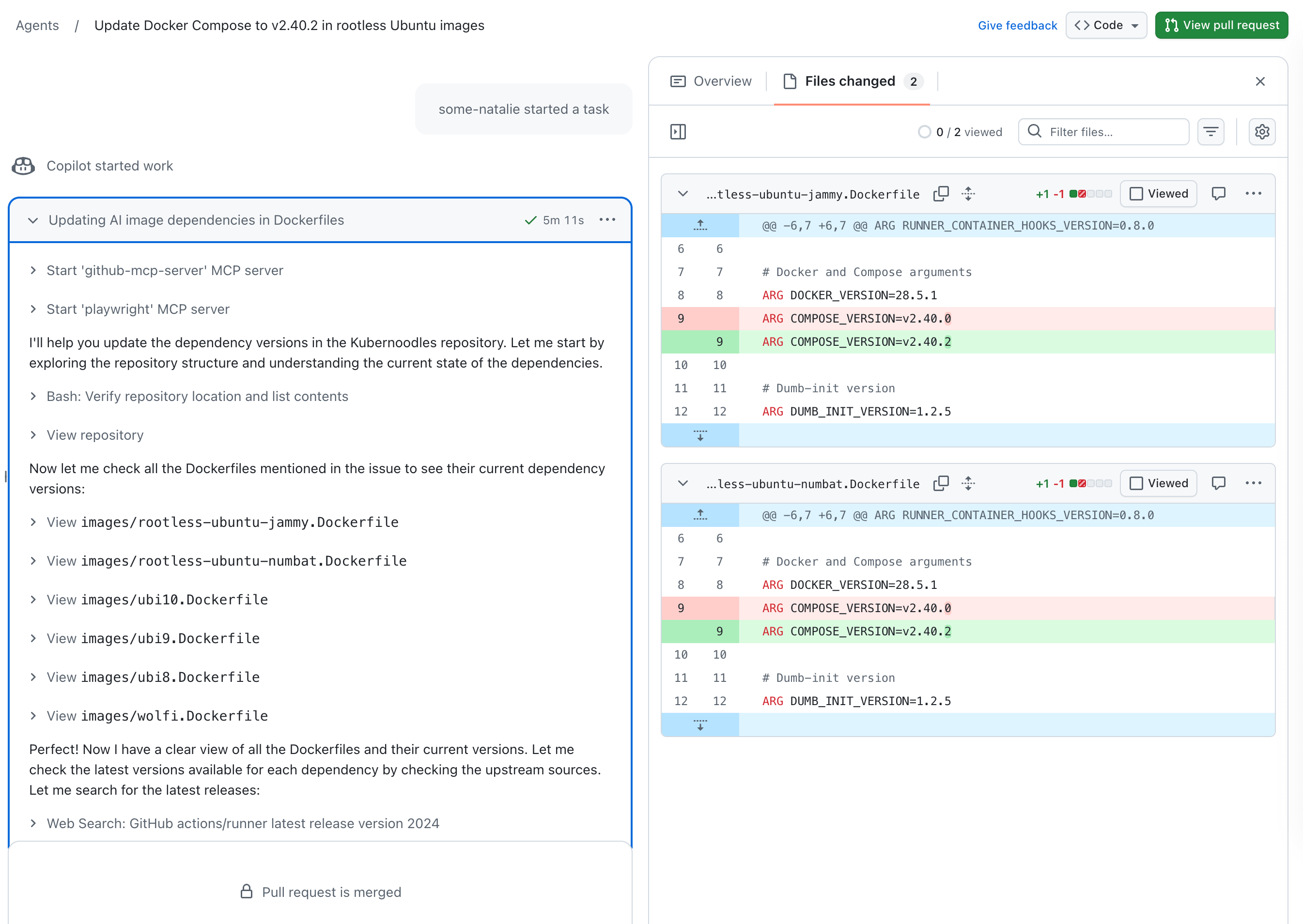 an example working session where robots do the boring work
an example working session where robots do the boring work
A pull request appears!
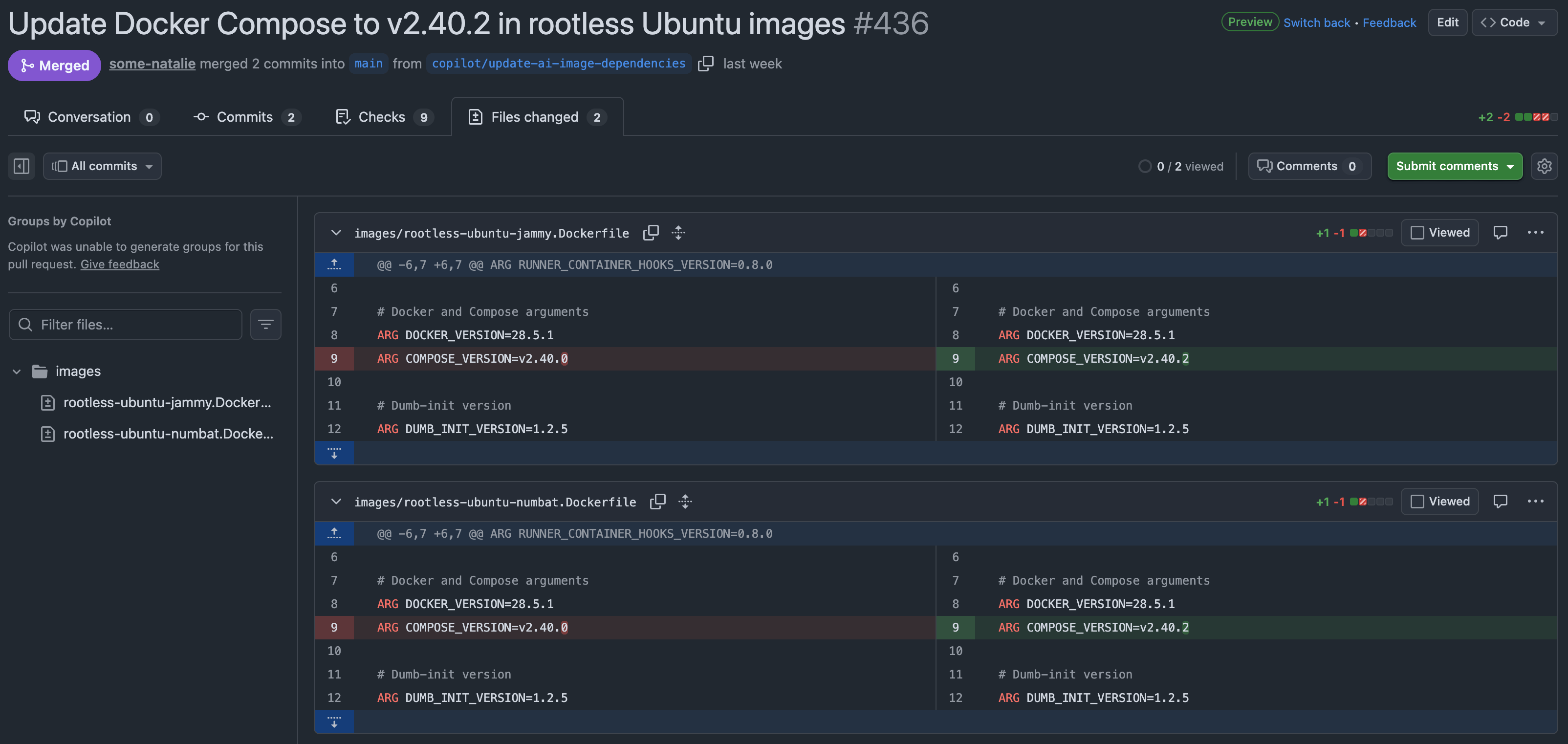
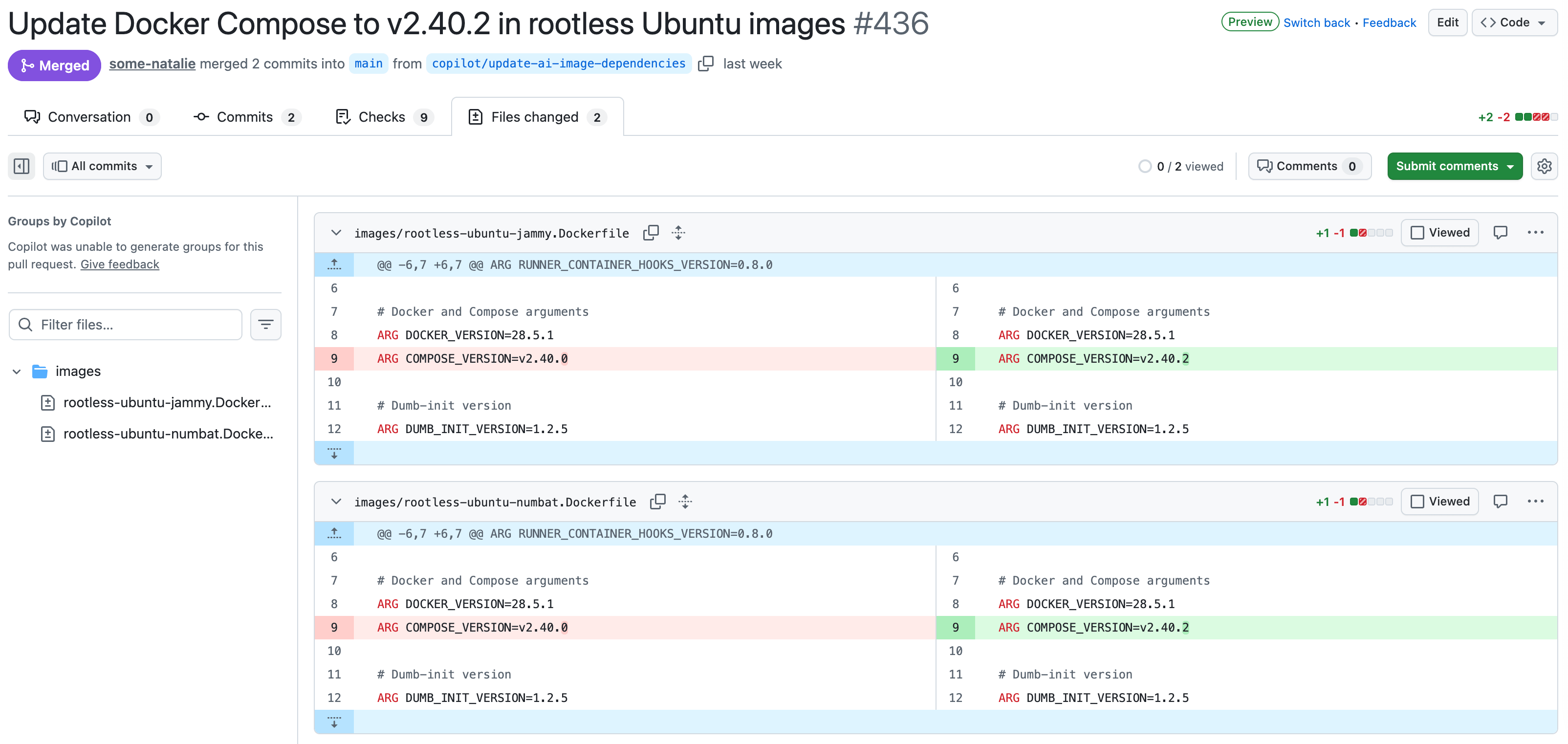 a wild, automatic pull request appears, bumping dependencies and triggering tests
a wild, automatic pull request appears, bumping dependencies and triggering tests
Parting thoughts
Now it’s chugging along, sending me delightfully simple PRs that bump dependencies. It’s been going for about 3 months now with little drama or garbage pull requests.
I’m still not convinced this was better or more efficient than a bit of regular expressions and sed. I got to practice some GraphQL that I haven’t used in ages. GraphQL seems to be one of those topics that AI coding assistants are particularly bad at, so all the code it gave me got trashed as a waste of time. However, the more boilerplate Actions setup was easy enough to tab through, then edit to scope permissions and format correctly. Once the bot ID business was sorted, there wasn’t much else to solve.
It’s easy to give AI less rigidly-defined dependency ecosystems to handle for me. It took an hour or so to whip it together, now it’s one less chore to do.
… just don’t forget to have lots of automated tests, away from anything that persists or is on your network …
Footnotes
-
This is why I spent so much time offloading tests for kubernoodles into ephemeral runners. The lack of persistence, small scoped permissions, and isolation for testing makes this delegation to robots safer. ↩
-
This is not my first silly Dependabot workaround or extension. I learned more Ruby than intended to make it batch dependency updates into a single PR years ago. Since this was before Dependabot even shipped to the self-hosted GitHub server, I cleverly called it dependabatch . ↩