Container Escapes 101 - seccomp in a nutshell
Seccomp 101
The lowest level of our container stack is the operating system on the host. These resources are accessed by any process in the operating system (a container or not) by system calls (syscalls ). These allow the process to interact with resources, like reading a file or writing to a network socket, and try to guarantee it plays nicely with everyone else sharing the same hardware. We could spend many hours talking about system calls, but this is all we need for today.1
The foundation we build on is the Linux kernel’s Secure Computing state, usually called seccomp . Introduced in the mid 2000’s, it has been critical to process security. It limits the system calls a process can make, allowing the OS to isolate processes better.
🪤 I think of seccomp as a mouse trap for processes - a process can enter, but the only way out is death. While alive, it can read and write to files it has open. It can exit nicely (exit()) and return a signal on if it was successful or not (sigreturn()). If the process tries to do anything beyond what it’s been allowed to by making a forbidden syscall, the kernel kills the process or logs the event (if not enforcing).
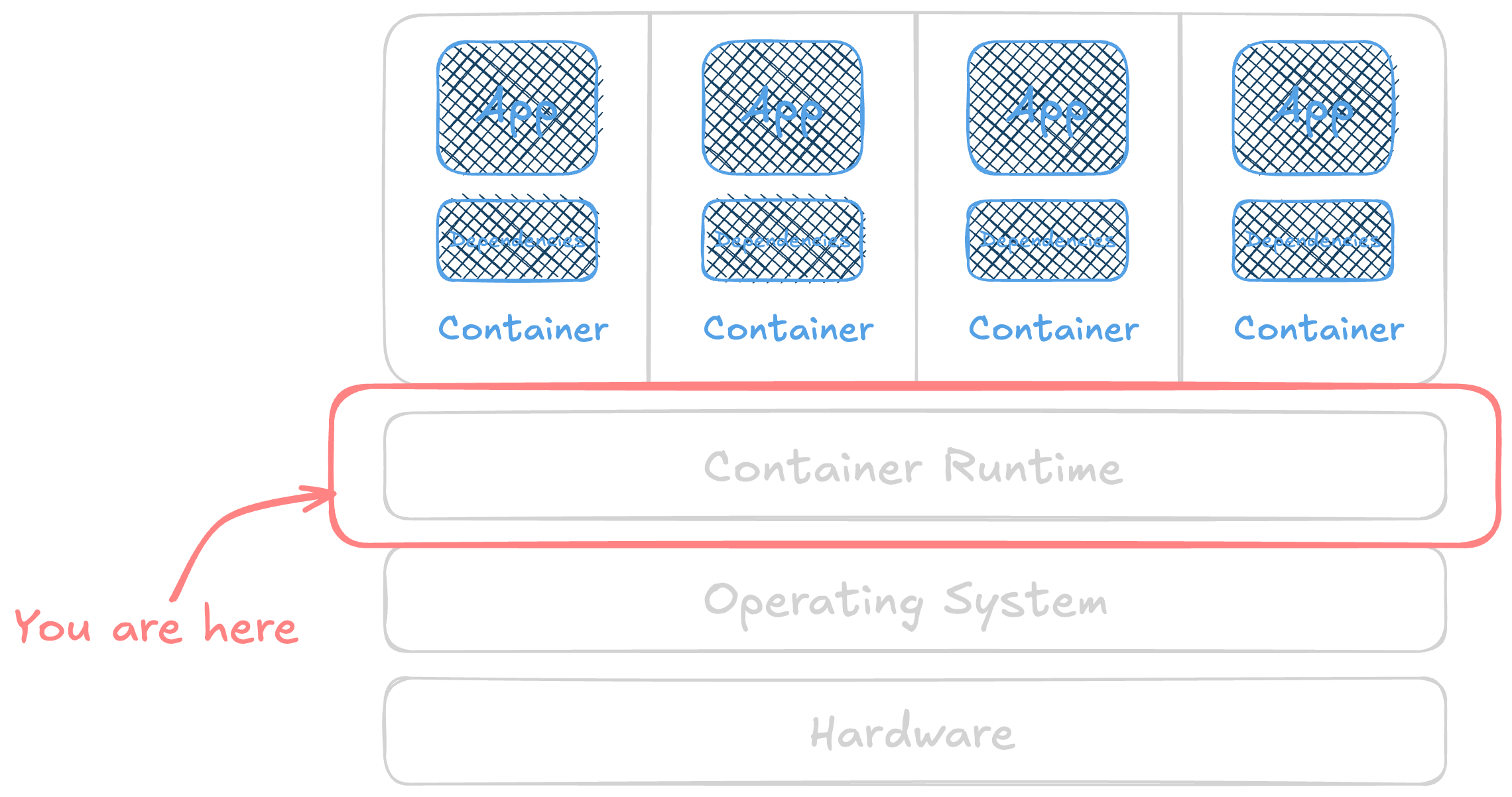
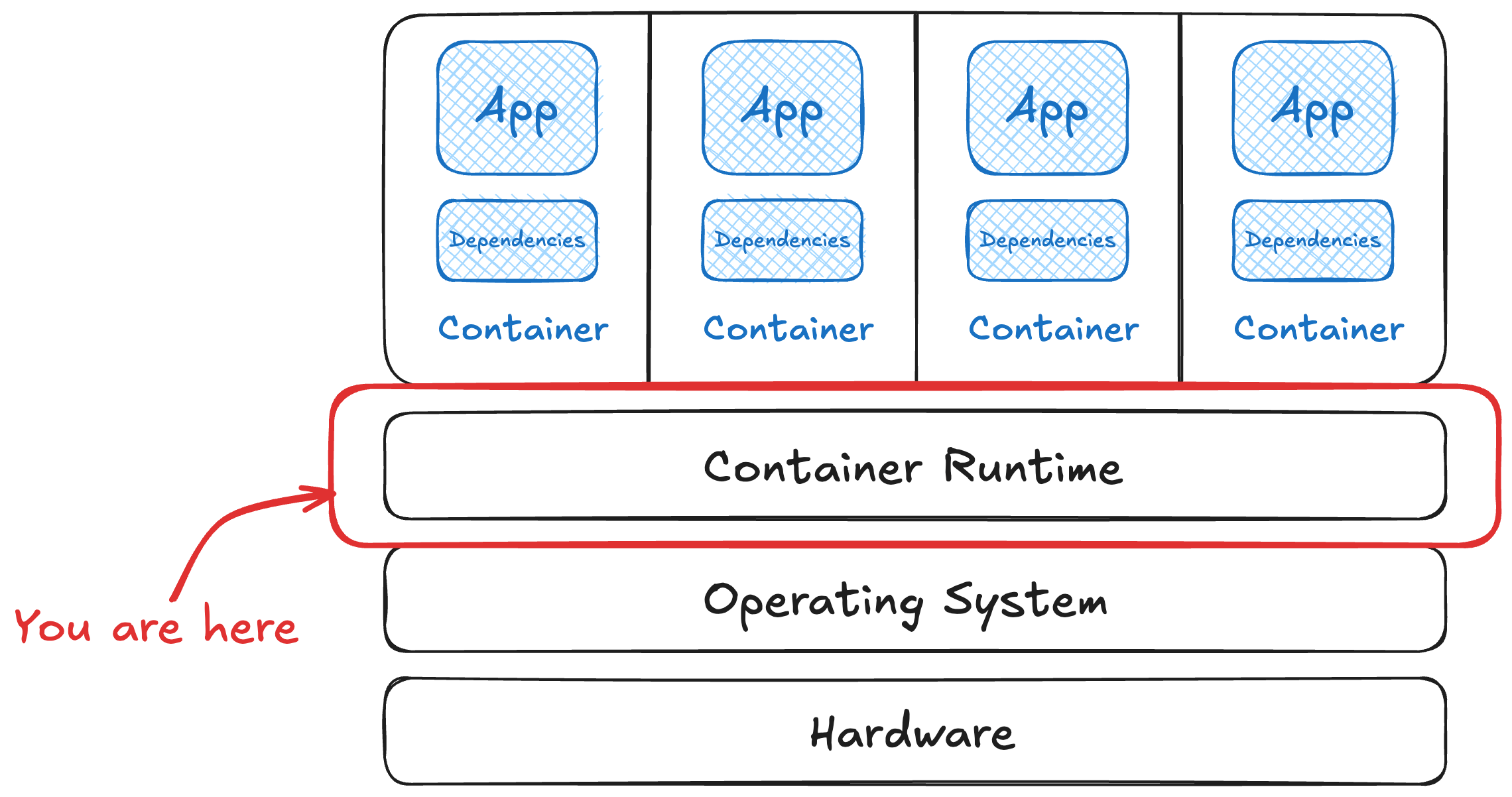
While seccomp profiles are enforced by the host operating system, they’re typically managed for containers in the runtime. Sometimes these configurations are applied in the container orchestrator (like Kubernetes), then passed through to each node’s runtime.
Configuring
Moving up a level, while there are hundreds of system calls in Linux, your containerized application likely only needs a much smaller set of them. Many container runtimes limit these by publishing and using a default seccomp profile. The Docker engine publishes good documentation on their seccomp profile as an example.
Seccomp profiles are implemented by the runtime to filter what a container can do. They are incredibly configurable. The defaults tend to be pretty sensible, allowing most workloads to run and blocking the highest risk system calls.
Detecting
This is where life gets fun! If you have a shell in your container, it’s simple to tell if seccomp is enabled and enforcing because it’s also in the output of /proc/self/status. There are two values.
Seccomp tells you if it’s enabled based on the value it returns.
-
Seccomp: 0means it’s disabled -
Seccomp: 1means it’s in “strict mode” (can do very little) -
Seccomp: 2means there’s a filter (most common)
Seccomp_filters will tell you how many filters are attached to this process and enforcing … something.
Enumeration

“Enforcing what though???”, you might ask. Sadly this is where life gets difficult. Seccomp works as a “one way door” that kills the process if it violates one of the filters. There are well over 300 system calls (syscalls) in Linux. A filter that includes or disallows granularly means there’s at least 2^300 possible combinations of yes/no answers for each - or many more possible combinations than grains of sand on earth. 🤯
Testing 300+ discrete features is doable, yet repetitive and noisy.
You’ll do it again and again and again until you get it right find a foothold to use in escaping this environment. You’d think there would be a better way … 🤔
Exercise #1 - Run containers without seccomp
When you’re troubleshooting and maybe accidentally leave it disabled, it’s easy to disable at runtime (or in configuration as code).
1
2
3
user@escapes:~$ docker run --rm -it \
--security-opt seccomp=unconfined \
ubuntu:24.04
❓ Can you verify that seccomp is disabled?
hint
You're looking for the same output shown above out of/proc/self/status
example answer
root@3a2ee70058ed:/# cat /proc/self/status | grep [Ss]eccomp
Seccomp: 0
Seccomp_filters: 0
It’s the exact same syntax to disable seccomp for Podman too. Since this is a really easy to commit into your deployments, it is quite possible to find it disabled in production. However, it isn’t too common because there are reasonable default settings in place.
Default seccomp profiles
Fortunately, most container runtimes have a set of sensible defaults that you do nothing with in order to provide some level of protection against our escape shenanigans. You do literally nothing to enable these. Instead, it takes effort to disable it (as we did above) and to change the behavior with custom ones. While each runtime may have their own opinions, most risky system calls are disallowed by default. These calls include messing with kernel modules and filesystem mounts.
- Docker docs on seccomp and seccomp profile JSON
- Podman seccomp profile JSON
Comparing these gets downright tedious. My fantastic colleague Mark Manning wrote a little tool to make this less of a chore and easy to visualize in Seccompare . If you’re doing any profile work at all, I highly recommend using it.
Exercise #2 - Custom profiles with strace

💞 It is a truth universally acknowledged that a program with settings must be in want of an engineer to customize it. 💞
It is safer to reduce syscalls in that it reduces the possible mischief you can get into. Think of it as making “living off the land” have less (and less bountiful) land. This assumption works perfectly in a universe where time is free, infinite, and has no monetary value. It becomes more difficult when you need to deeply understand the code base you’re working with and all dependencies at that level.
We’re going to
- Choose a program
- Choose a workload
- Observe that program under that workload to generate a list of system calls
- Create a deduplicated list JSON of those system calls in the right format
- Launch the program and workload
- Realize you missed something
- Iterate on #3-6 an unknown number of times
- Successful security? Perhaps??
Let’s do one together!
To start with, we’ll need to choose a program to create a profile of. Let’s use curl as a deceptively simple program.
1
2
3
4
5
6
7
user@escapes:~$ strace -o curl.txt curl google.com
<HTML><HEAD><meta http-equiv="content-type" content="text/html;charset=utf-8">
<TITLE>301 Moved</TITLE></HEAD><BODY>
<H1>301 Moved</H1>
The document has moved
<A HREF="http://www.google.com/">here</A>.
</BODY></HTML>
❓ What happened here? What did we do with curl?
answer
We hit a URL over HTTP with curl and got a simple redirect to another URL ... that's it.❓ How many unique system calls were made?
hint
grep -o '^[a-zA-Z_][a-zA-Z0-9_]*(' curl.txt should get you started.
example answer
user@escapes:~$ grep -o '^[a-zA-Z_][a-zA-Z0-9_]*(' curl.txt |\
sed 's/(//' |\
sort -u |\
tee >(echo "Total: $(wc -l)")
brk
clone3
close
connect
execve
exit_group
faccessat
fcntl
fstat
futex
geteuid
getpeername
getrandom
getsockname
getsockopt
ioctl
lseek
mmap
mprotect
munmap
newfstatat
openat
pipe2
ppoll
prlimit64
read
recvfrom
rseq
rt_sigaction
rt_sigprocmask
sendto
set_robust_list
set_tid_address
setsockopt
socket
write
Total: 36
These are all pretty standard system calls that do the basics of memory management (mmap and munmap), process control (execve and exit_group), and network sockets (connect and sendto, etc). While there’s nothing particularly special here, getting this data requires some understanding we didn’t need to have in order to use curl either.
Exercise #3 - Making our own seccomp.json file
Now that we have our list, it’s a somewhat simple task to create a JSON that allows only those syscalls. This is a pretty boring template, outlined below with a single syscall inside of it. From here, you add an entry for each one.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
{
"defaultAction": "SCMP_ACT_ERRNO",
"defaultErrnoRet": 1,
"archMap": [
{
"architecture": "SCMP_ARCH_X86_64",
"subArchitectures": ["SCMP_ARCH_X86", "SCMP_ARCH_X32"]
},
{
"architecture": "SCMP_ARCH_AARCH64",
"subArchitectures": ["SCMP_ARCH_ARM"]
}
],
"syscalls": [
{
"names": ["brk"],
"action": "SCMP_ACT_ALLOW",
"args": [],
"comment": "Allow memory allocation",
"includes": {},
"excludes": {}
}
]
}
The full file, with all 36 syscalls we identified, is in GitHub . I promise I hold nothing against you if you don’t want to do this exercise in copy/paste artisanal JSON crafting.
Using our new profile
Now that we have a valid seccomp profile JSON, let’s run curl in a container with it.
1
2
3
4
5
6
7
8
9
10
user@escapes:~$ docker run --rm -it \
--security-opt seccomp=seccomp.json \
cgr.dev/chainguard/curl:latest google.com
docker: Error response from daemon: failed to create task for container: failed to
create shim task: OCI runtime create failed: runc create failed: unable to start
container process: error during container init: error closing exec fds: ensure
/proc/thread-self/fd is on procfs: operation not permitted: unknown
Run 'docker run --help' for more information
⁉️ Aaaaagh, what happened?
answer
Running a program in a container, using the container sandboxing we learned about earlier, means we also need extra system calls.Adding more syscalls
We’ll add more syscalls. In this case, let’s add the syscalls needed for file descriptors and run it again.
1
2
3
4
5
6
7
8
9
10
user@escapes:~$ docker run --rm -it \
--security-opt seccomp=seccomp-2.json \
cgr.dev/chainguard/curl:latest google.com
docker: Error response from daemon: failed to create task for container: failed to
create shim task: OCI runtime create failed: runc create failed: unable to start
container process: error during container init: unable to setup user: setgroups:
operation not permitted: unknown
Run 'docker run --help' for more information
Now iterate for the next 6-600 hours until you get it right … or give up, disable it and move on.
(╯°□°)╯︵ ┻━┻
Hopefully “disable it” means using the default profile and not disabling seccomp altogether. This is the power of safe, scalable defaults.
There are tons of container tools that use these primitives to accomplish finer-grained access controls, file removal / size control, runtime enforcement, and more. If you’re trying to go down this path, here’s some hard-earned advice:
- The end product of these tools is only as good as the instrumentation and observability of your test workloads.
- It is possible to spend weeks creating these profiles only to need to revisit it on each update.
- Big vendors with fantastic (and large) engineering teams dedicated to maintaining these profiles and the instrumentation for custom workloads is probably more scalable than doing it yourself.
- Depending on the application, it’s also possible to accidentally break things silently. Relying on breakage to understand what works is time-consuming.
Parting thoughts
Seccomp is that mouse trap we talked about earlier that keeps processes from wandering (maybe maliciously) into dangerous territory. It’s also frequently configured as code, either in the runtime directly or in the orchestrator. Finding this code is probably the best way to know what’s going on instead of brute-force enumeration.
Custom seccomp profiles are great, but also hard. There is good commercial tooling to automate much of this, but it relies on your ability to know what workloads your app will see.
It’s quite possible to spend more time maintaining custom seccomp profiles than the security benefit they provide over sensible defaults. The mouse trap analogy holds here too … sometimes the best trap is the one that’s already been tested by millions of other mice. Invest your time consciously and understand it needs to be maintained.
The real win isn’t in crafting the perfect custom profile. It’s in understanding how seccomp works, knowing when it’s disabled (and why that’s dangerous), and making informed decisions about when the juice is worth the squeeze. Most of the time, those well-maintained default profiles from your container runtime are doing exactly what you need them to do.
📚 tl;dr - Perfect application profiling that nobody can maintain is just future technical debt with extra steps. Next up, with “tiny virtual machine” runtimes gaining popularity, how can you tell if you’re trapped in a container or a microVM?
Back to the index.
Footnotes
-
System calls and application/kernel interfaces are way beyond the scope of this talk. If you want to learn more, I found this interactive Linux kernel diagram to be super helpful! The Linux Foundation also holds a training course on the Beginner’s Guide to Linux Kernel Development . ↩