Orchestrating chaos and containers
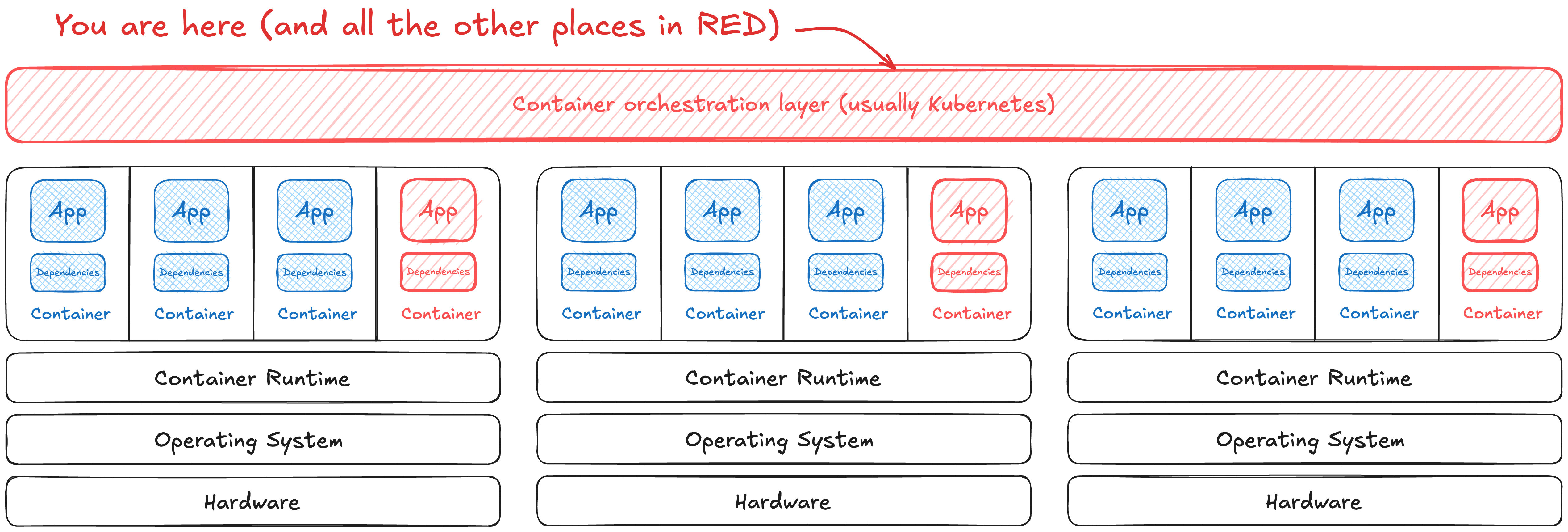
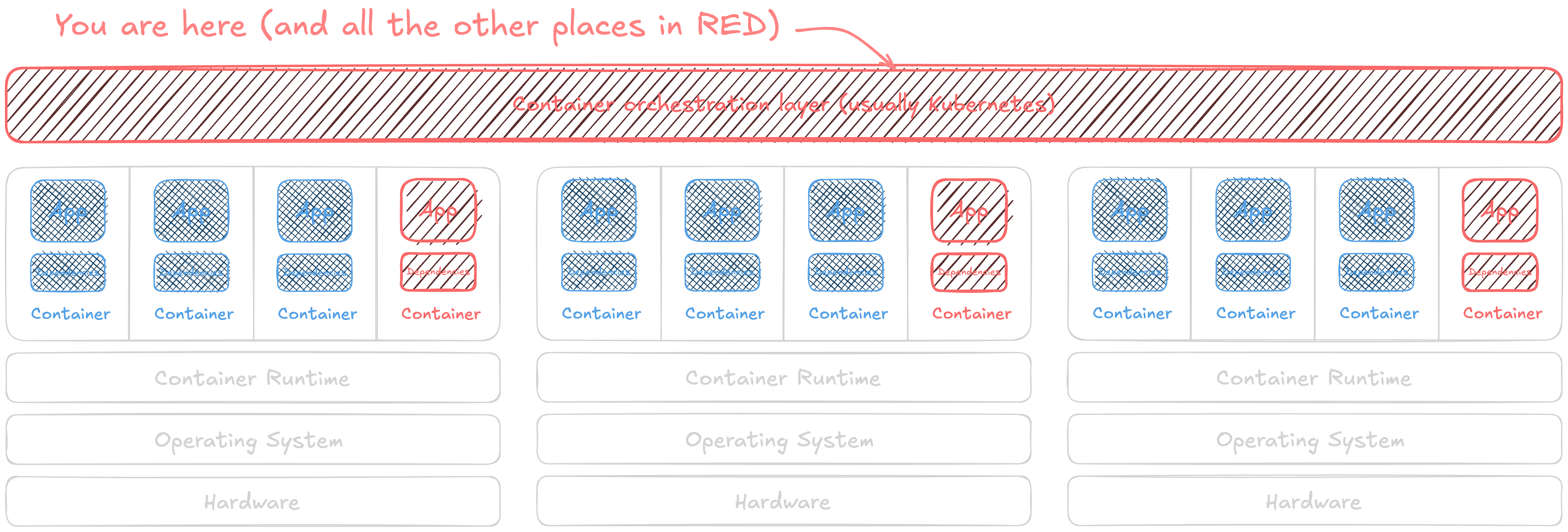
The magic of putting your application in a container is scaling to run even bigger workloads than could fit in a single machine. Container orchestrators have their own risks too. This new layer has its own permissions schema to learn and configurations to fiddle with.
The default these days is Kubernetes (open source) and vendored, opinionated versions like Red Hat OpenShift or SUSE Rancher. There are other orchestrators to know, though, such as Apache Mesos or Hashicorp Nomad … hell, even Docker Compose could technically count as an orchestrator. They all work somewhat similarly, where there’s a service on each node to understand resource utilization and a control plane to schedule work across all the members. We’ll focus on Kubernetes since it’s standard, but these concerns bridge any possible orchestrator.
This is part of a series put together from client-facing conversations, conference talks, workshops, and more over the past 10 years of asking folks to stop doing silly things in containers. Here’s the full series, assembled over Autumn 2025. 🍂
Global admin rights are a risky default

By default, new Kubernetes clusters have a single unbounded administrator (cluster admin). They do not have:
- Role-Based Access Control set up
- Single Sign-On configured
- non-admin users
- separation of resources by workload need
- … and a lot more …
Batteries aren’t included by default. Many of the cloud SaaS platforms and more opinionated distributions of Kubernetes usually have some or all of this easily set up for you, so long as you stay within the same ecosystem. As an example, it’s straightforward to integrate Amazon’s hosted Kubernetes (EKS) with their identity solution (IAM), but you may have to work a bit harder to use one of these things from another vendor.
😈 Exploit example - There are a ton of ways to grant way too many permissions to workloads. This is an easy one to find in clusters for CI/CD systems. Someone will want to allow GitHub/GitLab/Jenkins/whatever to manage resources on a cluster, so they’ll grant cluster-admin in the ServiceAccount for the CI system to use.
Here’s a (naughty) example searching for over-scoped deployments in Kubernetes using GitHub Actions:
1
2
3
4
5
# setup
- name: Create namespace for PR
run: |
NAMESPACE="pr-$(echo ${{ github.event.pull_request.title }} | tr '[:upper:]' '[:lower:]' | sed 's/[^a-z0-9-]/-/g')"
kubectl create namespace "$NAMESPACE"
Or for my GitLab crew:
1
2
3
4
5
script:
- echo "Deploying preview for $CI_MERGE_REQUEST_TITLE"
- |
NAMESPACE="mr-$(echo $CI_MERGE_REQUEST_TITLE | tr '[:upper:]' '[:lower:]' | sed 's/[^a-z0-9-]/-/g')"
kubectl create namespace "$NAMESPACE"
In both of these examples, the system is taking the title of the pull request (or merge request for GitLab) and piping it into a shell command. It was intended to create a namespace, but instead gave us some chaos instead. Creating a PR titled ; kubectl auth can-i '*' '*' --all-namespaces; echo , we learn that I’m a cluster administrator in whatever it is I’m targeting with the response being yes to my middle (naughty) command.
1
2
3
4
5
6
7
8
9
Run NAMESPACE="pr-$(echo ; kubectl auth can-i '*' '*' --all-namespaces; echo | tr '[:upper:]' '[:lower:]' | sed 's/[^a-z0-9-]/-/g')"
NAMESPACE="pr-$(echo ; kubectl auth can-i '*' '*' --all-namespaces; echo | tr '[:upper:]' '[:lower:]' | sed 's/[^a-z0-9-]/-/g')"
kubectl create namespace "$NAMESPACE"
shell: /usr/bin/bash -e {0}
The Namespace "pr-\nyes" is invalid:
* metadata.name: Invalid value: "pr-\nyes": a lowercase RFC 1123 label must consist of lower case alphanumeric characters or '-', and must start and end with an alphanumeric character (e.g. 'my-name', or '123-abc', regex used for validation is '[a-z0-9]([-a-z0-9]*[a-z0-9])?')
* metadata.labels: Invalid value: "pr-\nyes": a valid label must be an empty string or consist of alphanumeric characters, '-', '_' or '.', and must start and end with an alphanumeric character (e.g. 'MyValue', or 'my_value', or '12345', regex used for validation is '(([A-Za-z0-9][-A-Za-z0-9_.]*)?[A-Za-z0-9])?')
Error: Process completed with exit code 1.
We could do all sorts of other shenanigans in our PR titles now, like deleting all the things in the cluster, or installing a cryptominer to steal resources, or just dumping secrets stored in the cluster. The possibilities are confined to whatever you can fit in the maximum 72 characters of a PR title.
Selectively scope privileges as much as possible for the orchestrator you have and the workloads you need. Use “paved paths” to reduce edge cases. For the given example, using a deployment operator (such as ArgoCD or FluxCD) could prevent a lot of the shenanigans we could get into by relying on direct
kubectl. It is also wise to not givecluster-adminto a CI system and rewrite the workflows to prevent shell injection. Reading the documentation and asking for peer review are valuable ways to improve the posture of your application.
Unauthorized access to the orchestrator
There is nothing special about unauthorized access in containerized applications versus any other application. However, there is an uncomfortable pattern of treating the node’s operating system like any other Linux box. You’ll install some endpoint detection, some log forwarders, add an account for your infrastructure scanner to SSH in and check things, etc. If any of these accounts or programs are compromised, getting access to the other nodes via the orchestrator is as simple as running kubectl.
😈 Exploit example - Building on the example above, if I were to title my PR to dump all of the cluster secrets, I’d get the credentials to be someone I’m not and do naughty things. Similarly, getting ahold of an SSH private key or cracking what’s in /etc/shadow could get me a login.
Locking this one down means strengthening, then reducing or eliminating host-based logins. Instead, rely on an external authentication service - both for node logins and for your orchestrator. Damage-reduction services, like encrypting the data at rest and separating host logins from cluster administration from logging in to the application that runs on the cluster, are also valuable.
Open networking
By default, all pods in a Kubernetes cluster are allowed to communicate with each other, and all network traffic is unencrypted between the containers. This isn’t a bad thing. Instead, bring your own policies and tools to secure as fits the application and its’ risks. There are lots of options for cloud-native networking and service meshing. The network policy docs are a good place to start.
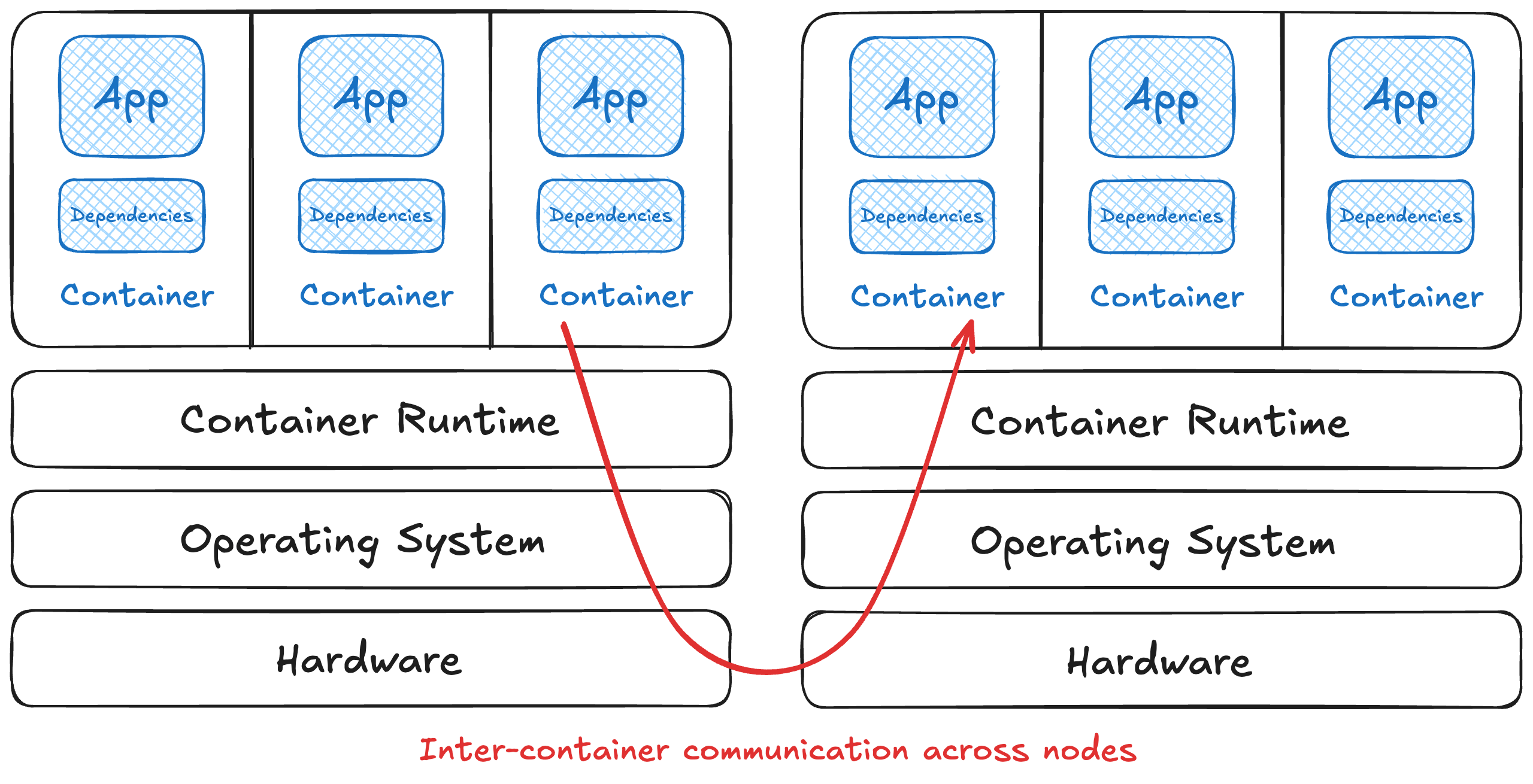
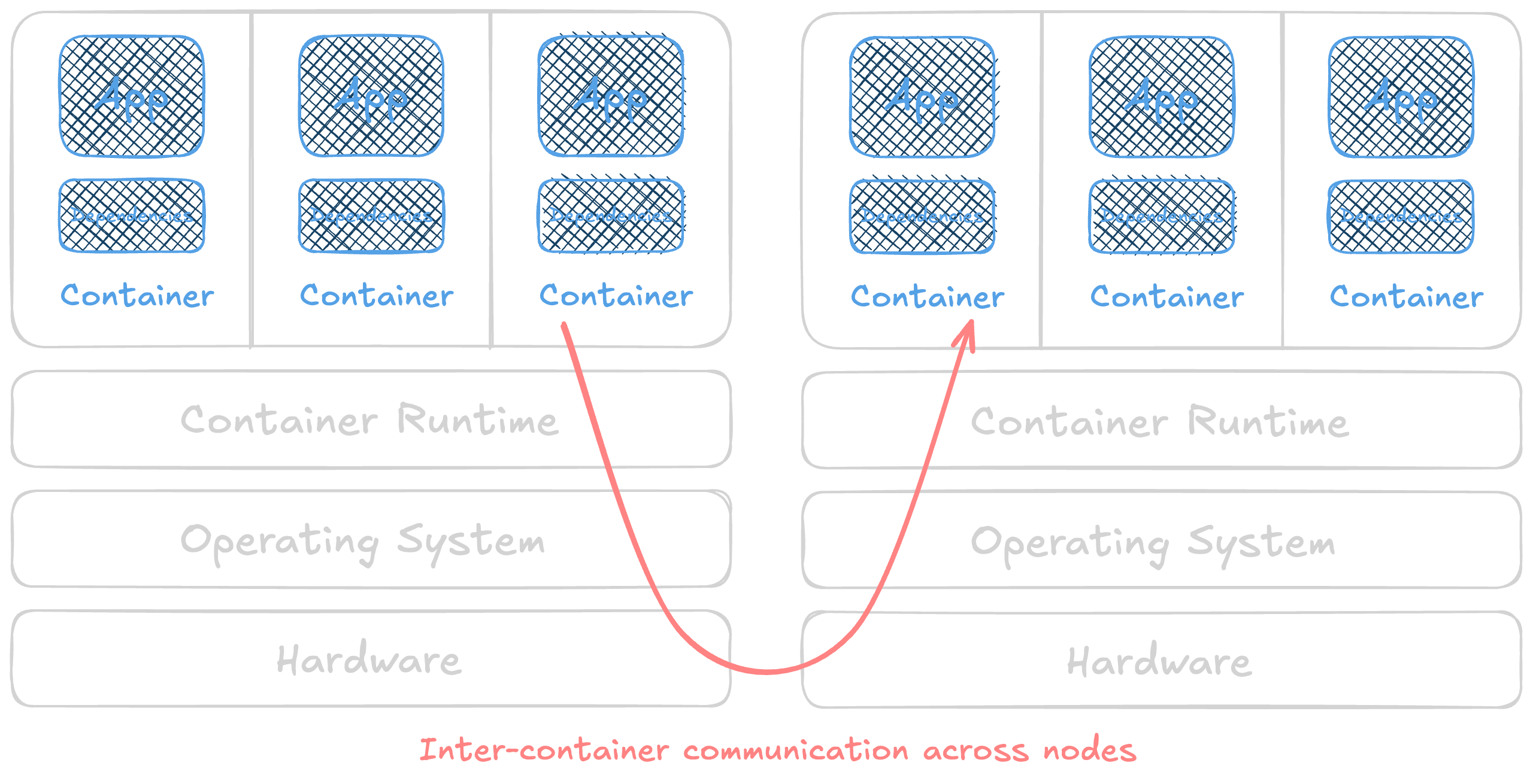 Kubernetes networking by default
Kubernetes networking by default
Just … don’t forget to do this, alright? Much like the login problems above, this is more about being overly permissive to save time and not finish locking things down. Pick something that’s well-supported and mature, then go with it as long as it fits your needs. 🤷🏻♀️
All workloads are not created equal

Containers never changed that development or testing resources shouldn’t touch production, or that customer info should be handled differently than mock data, and so on. Sadly, there’s two common misconceptions that bear repeating here.
Containers don’t contain of much of anything. Namespaces aren’t partitions at all. It’s a high-level abstraction that gives an ability to group all sorts of different resources (policies, networks, storage, etc.) by a label. It can be used to set policies about resource usage too.
This makes securely co-tenanting sensitive data or workloads difficult. While the documentation on multi-tenancy is fantastic, it’s still better to try not to mix data or workloads that you wouldn’t have without a container. There are several projects to make this easier, too, such as:
- MicroVMs or other alternate container runtimes
- Network policies are neat
- Don’t forget about storage, either!
⛓️💥 Your cluster, and all the things it can connect to, is only as secure as the weakest workload in it. ⛓️💥
😈 Exploit example - One of my favorite risky practices is nested containerization (eg, “Docker-in-Docker”). It is a highly privileged workload that is simple to do, but hard to secure or mitigate for some uses. It’s also common in enterprise CI systems1. This means that, by design, we have a workload running with extra capabilities that can build/run arbitrary user input from the version control system. Isolating this is the bare minimum to prevent it from contaminating other workloads. (or, I learned about that GitHub Actions shell injection problem as shown above first-hand as my users spawned cowsay as a privileged process … 🙊)
Resist the urge to create One Cluster To Rule Them All until you
- understand the risks on all the workloads
- and have a ton of mitigating controls (hardened runtime, deny-by-default networking, etc.) in place
- have a friend double-check all of that because peer review is good
Nodes trust each other
This entire system of resource pooling to schedule workloads only works because nodes trust each other. The nodes work together to create one bigger system. A compromised node can compromise the entire cluster. From a node, I can add/edit/remove workloads with basic Linux commands or access secrets stored on the filesystem.
This increases the risks of
- leaked credentials (kubeadm tokens, .kubeconfig files, etc.)
- a toxic node accessing so many other resources
- weak authentication between nodes
As the system is a bigger target to compromise.
😈 Exploit example - My first stop is still sifting through a version control system for committed secrets and tokens generated to join a cluster are no exception. While many of these are likely useless or short-lived, I’d bet there are a few goodies among the 60+ thousand results here. More importantly, limiting your search to your own organizations can help expose what’s out there.
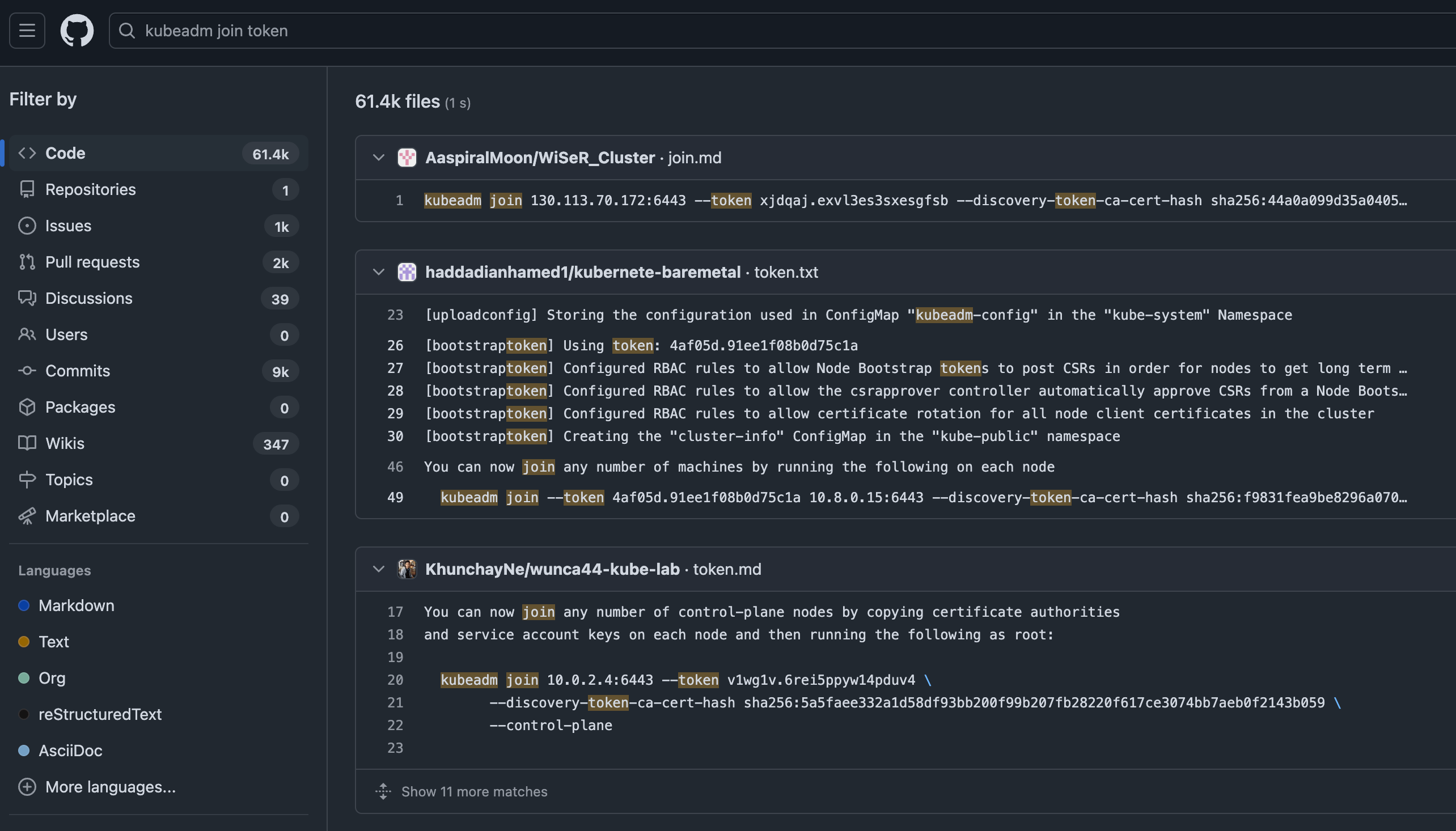
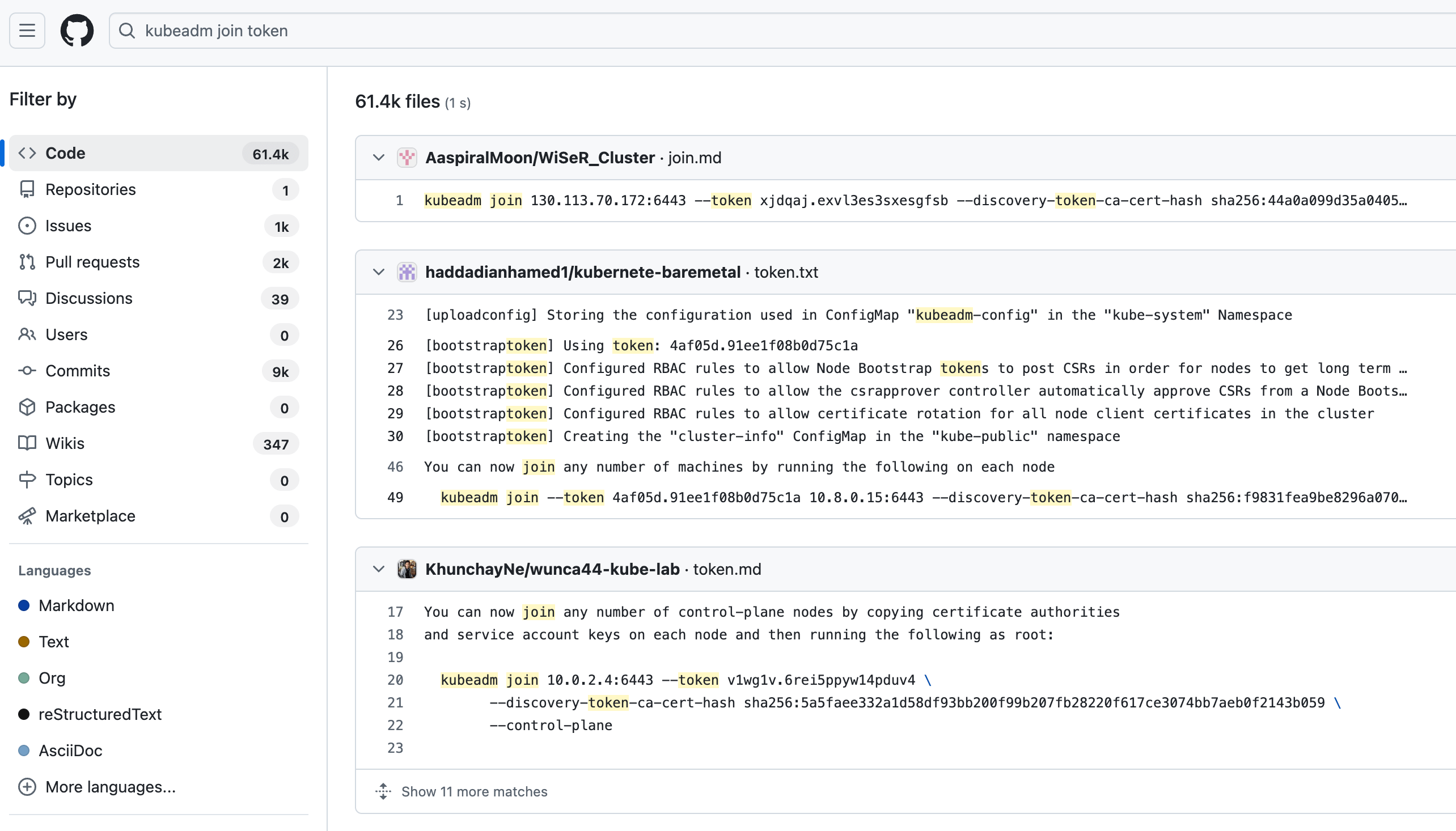 61,000 results for “kubeadm join token” in public repos in GitHub … how many are in your private version control systems?
61,000 results for “kubeadm join token” in public repos in GitHub … how many are in your private version control systems?
😈 Exploit example - Yet another problem building on our overscoped cluster from before, kubectl get secrets --all-namespaces -o yaml will dump all the secrets into a yaml file into stdout and easily fits in the 72-character limit of a pull request title. Who knows what goodies are hidden here?
Secret management didn’t get any less important or easier to do with an orchestration engine running containers. Make sure adding and removing nodes is also strongly authenticated as well.
Some parting thoughts
Most of this is just an extension of the same basic hygiene tasks, applied for running multi-node systems. Secret management is important, yet tedious. Pick an orchestrator with a reasonable community and vendored support available to you if you want it. This is why there are so many security configurations and vendor certifications and tools targeting the orchestrator layer. This is a great place to start learning how to secure your orchestrator.
Up next: All of these containers are images … somewhere. That “somewhere” is a registry. What risks can we find in our container registry? (back to the summary)
Footnotes
-
I went from nothing to bare-metal self-hosted Kubernetes in production in about 6 weeks with a tricky workload (enterprise-wide CI systems) … and I messed up a lot here. Thanks to some benevolent mischief makers for poking holes in my terrible ideas, helping me lock things down, and then doing it again. And again. And again. Y’all know who you are, and “thanks” doesn’t begin to cover it. 💞 ↩