Following the 'golden image' road: best practices and pitfalls

The rise of software supply chain attacks, strengthened security requirements of compliance frameworks, and the speed and complexity of software development have all driven the need for enterprise open source standardization, often called “golden image” programs. Even while many teams agree on how important it is, few feel comfortable tackling a large and fragmented challenge like open source software delivery, especially across diverse and disparate mission needs. Let’s share some hard-earned lessons in building adoption of a “golden image” program across large, heavily-regulated industries.
This is a write-up of slides presented at Open Source Summit NA 2025 on 24 June 2025 in Denver, CO.
🎥 YouTube video , if watching a video is more your speed
I’ve built and led a developer platform that consolidated thousands of users, then helped a bunch of other teams do the same. Having seen it done well, made many terrible mistakes of my own, and also seen many dumpster fires … miniature fiefdoms … ways to improve … let’s share some stories!
The things we all know
- Security good ✅
- Vulnerabilities bad ☠️
- More software probably means more vulnerabilities
- There are lots of known vulnerabilities (CVEs) and no great way to enumerate them at the scale needed now
- If you have 50 CVEs per image and 10 pods in a ReplicaSet, how many times can one copy/paste remediation notes into a spreadsheet until your GRC team all file for carpal tunnel syndrome? 😅
- Do you have enough people hours to deal with this? 🤔
And in a bout of self-awareness, we vendors don’t always help this problem.
BEHOLD! The "iceberg slide" in every cybersecurity sales pitch.
 image search results for “open source security iceberg”, with many vendors represented and for some reason, Bonzi Buddy
image search results for “open source security iceberg”, with many vendors represented and for some reason, Bonzi Buddy
The iceberg slide is a decent metaphor even if it’s overused. Ten years ago, I definitely remember being told that the “ratio” of code your company writes to code your company ships being 70/30 during some random sales pitch.
Or maybe it was 80/20. 90/10? 98/2??? 🤷🏻♀️
The exact ratio doesn’t really matter.
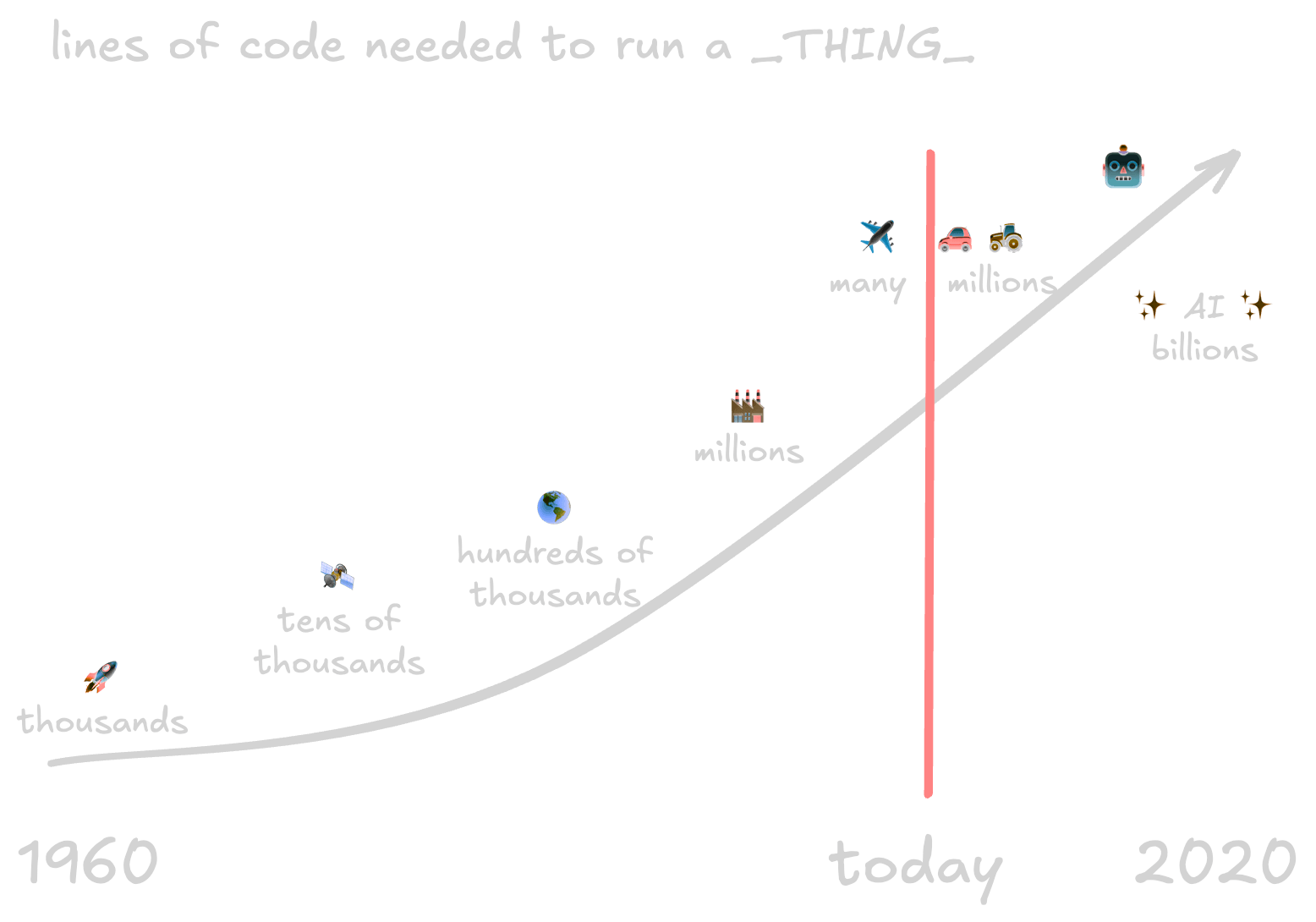
 the lines of code needed to operate something, from the first rockets to the newest AI systems, from 2014 or so
the lines of code needed to operate something, from the first rockets to the newest AI systems, from 2014 or so
Instead, I think of this (equally dated) slide showing the approximate lines of code needed to run something. Apart from the optimism that 2020 was going to be a great year and AI was going to be ✨ fantastic, ✨ it’s still true. A modern car or tractor has hundreds of millions of lines of code, but only thousands were needed to launch humanity into space. Humans didn’t magically become able to write/maintain several magnitudes more code in a few short decades. We build on each other.
So … do you know what you’re running? 🙈
Life before devops
This isn’t a new problem, brought about by “devops” or “agile” or anything else. As a pimply-faced youth , I worked at a school district running around with some screw drivers and floppy disks. We operated in cycles, as “sprints” hadn’t been invented yet.
- Every other year hardware refresh
- Yearly hard drive wipe
- Monthly image update and patch curation
- “Please reboot your computer” was about a dozen different group policy objects
The cycle didn’t account for exceptions when “I need a new piece of software to do COOL CLASS THING!”
We still had “golden images”, too. The process isn’t that much different than what many teams are doing now either.
- Curation and patch management (this was before Patch Tuesday) wasn’t easy
- Configuration drift happened, even with “reboot to reset” software like DeepFreeze
- Rolling out a new “golden image” meant
- Identical hardware
- Installing a vanilla OS and all patches, configuring some local admin account
- Installing and configuring software - a browser, Office, CAD, some antivirus stuff, etc.
- “Freezing” the image, meaning it stripped UUIDs like a MAC address
- Prepping the system to get this and more from an on-site team (young adults running around with floppy disks)
Knowing what you’re running has always been both important and difficult. Managing edge cases or business exceptions in a “golden image” isn’t new either.
Containers didn't cause this and they didn't fix it either.
As cheesy as it sounds to say “people, process, and technology”, that’s actually the order we’ll be going in for good reason. Each of these is an order of magnitude easier than the one before.
First, the people problems

I’m convinced that everyone who cares about something in a big organization has felt like they’re screaming into the void. Don’t do this. Instead, manage the people first.
Who cares about this?
- Security?
- Developers?
- Infrastructure?
- Finance?
- GRC?
Probably everyone, but differently.
Each stakeholder multiplies your project’s complexity. Managing and addressing their concerns is how you Get It Done, not end up like the poor dude to the right.
I just want to … not get paged on the critically boring
Security software is universally noisy, to the extent that not being noisy is a critical selling point for all of them. A central place to create images across the organization helps this by reducing duplicative work on many copies of the same application. A single source of truth means it’s possible to patch and test it once, then ship it across many teams. It simplifies and speeds the path to remediation.
All this good news isn’t without a cost. Security typically provides both human hours and budget towards paving and maintaining a “golden image” program.
I just want to … ship cool new features
Building things (usually) isn’t all chores like running infrastructure updates or bumping dependencies, hoping test cases catch anything that breaks. Your business isn’t bumping dependencies, but delivering value to users. A central program to build and maintain standard images creates specialists in infra maintenance. This team needs to remain close to the user teams or there’s a risk of building things no one will use.
I just want to … run production efficiently
Operations usually bears much of the maintenance costs, but they stand to also save the most time and effort across each team. A couple of operations lessons I’ve learned the hard way.
- The longer you go between updates, the more likely things are to break.
- Tests may not be fun to write, but they will always save your butt.
- Canary or blue/green or ring deployments are your friend.
- If touching production scares you, fix that first.
Golden images centralize “acceptance criteria” burdens. The reduced costs for bandwidth, storage, and compute are likely not insignificant, but human hours almost always cost way more.
I just want to … understand our costs
If you’re not already measuring your costs, it’s nearly impossible to measure the savings either. It’s difficult to track the labor costs of
- Software curation
- Security (internal code, ingesting from the internet, scanning, ops, etc.)
- GRC documentation and remediation and submittal compiling
- Patching and remediation of vulnerabilities
Each team doing this is repeating work done several times over by others in the organization. It’s easy for this to be an “invisible cost” despite it being worth measuring.
I just want to … pass the audits needed to do business
Please don’t fall asleep! A key part of the business is usually
- ✅ Business continuity
- ✅ Audit readiness
- ✅ Change management
Not everyone should have to be an expert in whatever-acronym-you-need in order to enjoy their job. There’s a million acronyms specific to regions (FedRAMP) or markets (PCI-DSS), and a bunch more, each with their own intricate needs. Make it simple on as many folks as possible.

Pitfall: assuming everyone is as passionate about this as you are
This is a job. Everyone at your company, to some degree, works for money.
Not only for money, but … uh … I do show up to my job to get paid. So does basically everyone else.
✨ This is okay to acknowledge! ✨
I once had a mentor say that “there’s no patch for human stupidity.” That’s true, but it’s also not realistic or fair to expect everyone to want to be intimately involved with the details of each project decision. I’d like to do the thing I’m passionate about, that I get paid for, that I took this job to do. If a team is only as strong as the weakest player, securing the weakest link uplevels the entire team.
More process than sense (sometimes)
Once you get some stakeholder buy-in, congrats! You’re a little bit further along and have a lot longer to go. Here are a few places where I’ve seen teams build out processes that get adopted and scale well.
What goes into your golden image?
First, think about what’s going into each image.
✅ Custom SSL certificates for your CASB or security proxy. These are in nearly every large organization, intercepting encrypted traffic and inspecting it. If it’s configured correctly, users won’t notice it at all. If it isn’t, the first suggestion on every search/AI prompt/forum is to disable cryptography altogether. Configure it for all teams correctly so they don’t have to do it.
✅ Internal package repositories need configuration. Another enterprise standard, the internal package repository (and disabling any other sources of software) is something to configure once for everyone correctly to ensure it gets used and not bypassed.
✅ Any custom configuration should be set up first. Any other customizations like logging, caching, entrypoint scripts, etc. should be set up too.
✅ OCI labels … future you will thank present you! Containers can have a near-infinite number of key/value pairs stored as metadata labels. Lots of tools use these labels to display information about what’s running. Good things to put here include central support portal URLs, email aliases or group message channels for notifications, when it was last built/updated, who maintains it internally, and so much more. These are completely free to use and set, so make as many as you need and feel free to always add more.
✅ As little as possible and as many as necessary. In general, it’s easier to maintain 10 small images than 1 large one. It’s also usually not worth the fight about how many SQL databases or other “near duplicate” functionality you already have. This isn’t the time to clean up your tech stack too. While it’s less to maintain in house, it’s adding one more hurdle to adoption in refactoring or migrating tech before adopting the central image.
How fast can you change?
You will forget something, even if especially if this is a long process with many folks who have input into the thing. The teams I see do this successfully and maintain it long term have a process that looks a lot like this:
flowchart TB
A(fab:fa-docker User requests a<br>new container image<br>or changes to image) --> B[Ticket Portal]
B --> C(fa:fa-scale-balanced legal review)
B --> D(fa:fa-shield-halved information<br>security)
B --> E(fa:fa-server infrastructure<br>operations)
E --> F{allow or deny?}
D --> F
C --> F
F -->|allowed| G[add to golden images<br>enterprise platform]
F -->|denied| H[user communication<br>explaining decision]
The time from request to decision is about a day (or less). The faster you can return a decision, the fewer thumb drives get used to just get it done without any blessings or blocks from a central authority. Speed is security. This same speed will also help you remediate any vulnerability that makes the nightly news quickly.
Evangelize - top/down AND bottom/up
Enterprises are incredibly noisy places. It’s easy to get hundreds or thousands of emails a day, distribution lists and team chat tools and a dozen other collaboration notifications, and more. Don’t get lost in this. Instead, it’s most effective to evangelize in two ways.
- Top/down executive alignment will help the project’s longevity and visibility. This avoids the question of “why are we spending money on things that don’t break”, as the folks who provide money or headcount to fix this problem are
- Bottom/up expansion is what drives adoption. Keep in mind that if a user has a problem, it’s our problem. You’ll also spend a lot of time paving paths to show folks how easy it is to do less, yet accomplish more.
No one can adopt a paved path that isn’t on the map. 🗺️

Pitfall: “chargeback” or enterprise cost attributions
I’m guilty of this hubris. I built a system to do this for around 50 applications and tens of thousands of users. It didn’t start out this way. 😬
I was asked to figure this out for 5 applications and a few thousand users. How hard could it be? It’s just a bit of Python.
This “bit of Python on a cron job” became much more.
- The data needed to be stored somewhere. Let’s add a SQL database.
- That database’s schema needs to be able to change. Let’s add a schema management tool.
- The raw data isn’t exactly what’s needed, so let’s write some ETL pipelines to sanitize it.
- Okay, but usernames don’t line up between our identity management tool, our HR tools, and the tools we need. How do we normalize this accurately?
- We need more than cron now. Let’s move to something that can run tasks in parallel.
- … and so on …
This information is needed to understand who’s paying for the work on “golden paths” work. It’s much harder to recover costs from business units than it is to fund it as overhead. This is something you can revisit or build later. It doesn’t have to be done first in order to build a better paved path for your teams.
🪦 Many initiatives die here. 🪦
Rome was not built in a day
Tons of talk about “tiger teams” and “the point of the spear” and other somewhat aggressive names for your first set of users. It’s important to get some first folks using it, but focusing here is just not how enterprise changes happen. It happens more like this:
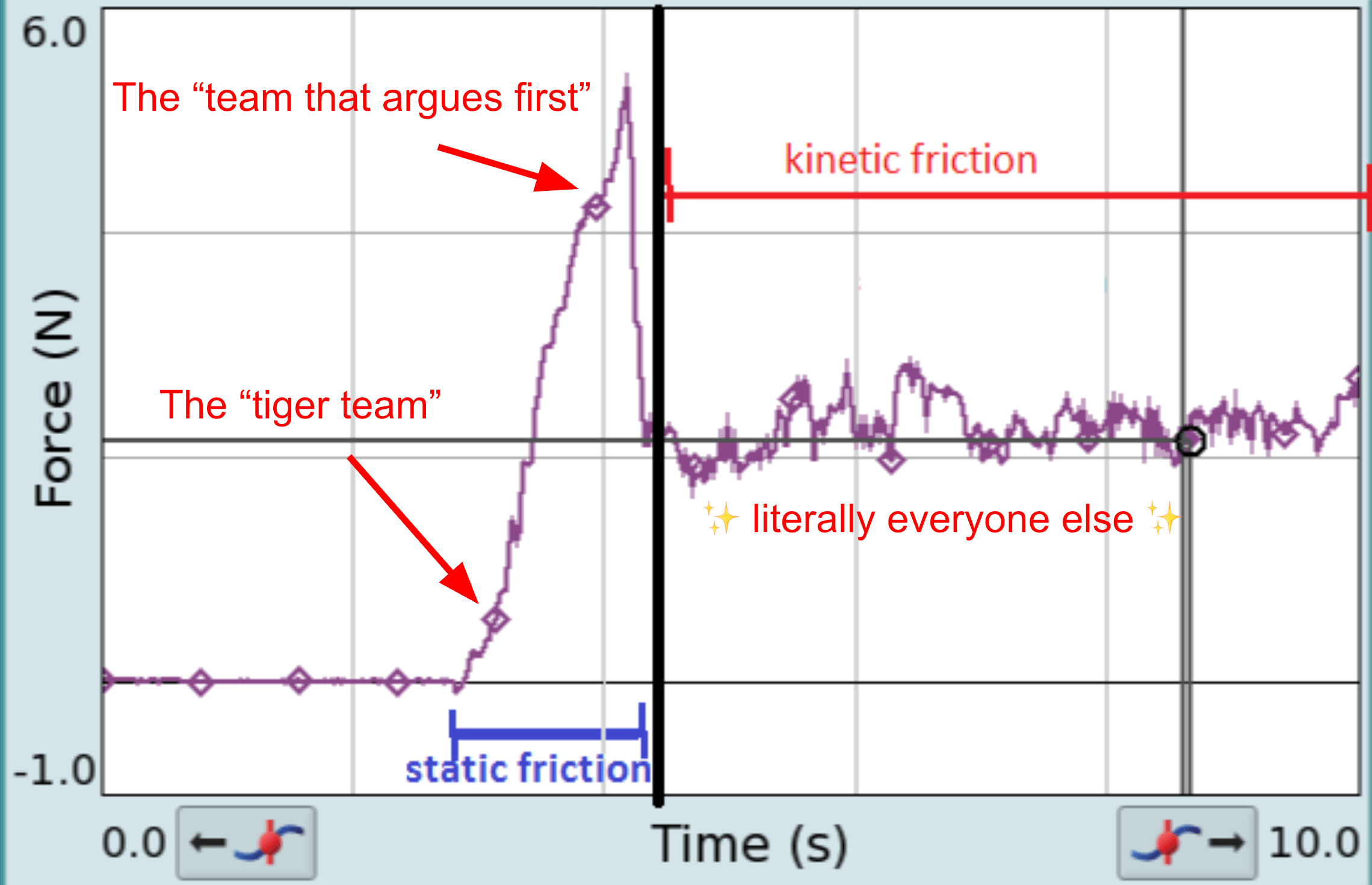 the coefficient of enterprise change friction, not as written by Sir Isaac Newton
the coefficient of enterprise change friction, not as written by Sir Isaac Newton
When you pull a box along a driveway, you pull and pull and then when it moves, keeping it moving requires less force. That’s a well-known principle in physics called the “coefficient of friction”. It’s also a decent description of enterprise changes. The folks that want to be part of the “tiger team” are already invested in trying new things. They don’t usually require a ton of engineering or executive hand-holding to move along. The team that gives you the first good fight is the one where there’ll be tons of work put into it. However, once rolling, most teams aren’t too hard or easy to onboard.
Pitfall: Only measurable things go on OKRs 😬
Lastly, don’t let performance management sideline the project. Instead, work with it to highlight the impact of the golden images your team has built and deployed.
Good example goals
- 💎 Onboard 5 teams (each under 50 users)
- 💰 Cut egress costs by
x% - 💤 Decommission
specific enterprise systembyDATE
Reconsider how you write these
- 🚮 Turn down shadow IT infra by
x%… by definition you don’t know how much shadow IT you have! - 🚢 Ship features faster
- 🙈 “improve security” without a specific target
Don’t make the same mistakes that I did. Highlight impact first, then don’t also complete a dozen side quests to Just Do The Thing.
Technology is the easy part … and a ton of hard work
Wow! We made it past the difficult and squishy problems and into the technical challenges. This is straightforward, but it’s foolish to go in believing it’ll be easy.
Misconceptions in (some) enterprises about OSS
There’s still plenty of misconceptions I run across helping teams build out a central source for their open-source software. It’s usually some combination of these:
- “I read in a whitepaper that
X%of contributors are unknown” - Unknown = bad
- My GRC/security/legal team objects
- My security scanners alarm
-
X%of public repositories are neglected or malware or (whatever) 😱
Followed by “but it’s free.” 🤑
But never acknowledged as actually, genuinely better than what could be done in-house. 🥰
Most companies aren’t in the business of building amazing databases, or container orchestration engines, or programming languages. These are tools to build widgets to sell or any number of other things.
Choose where and who you trust carefully
Open source maintainers are fantastic guardians for their projects.
Commercial packagers aren’t, for many reasons. They’re not fast at changing, as many rely on stability and bringing fixes backwards in time. Others roll forward without much support. Truthfully, it’s hard to provide support on an ever-shifting deep nest of dependencies. It’s even harder to run a sustainable business from that.
For the company I work at now, this means building everything directly from source code, recursively from a bootstrapped GCC compiler. The thinking is “you can’t fix what you don’t own,” and that’s true. This depth is how we think about “defense in depth.” It allows everyone to understand risk and mitigate uncertainty about what’s in the software running.
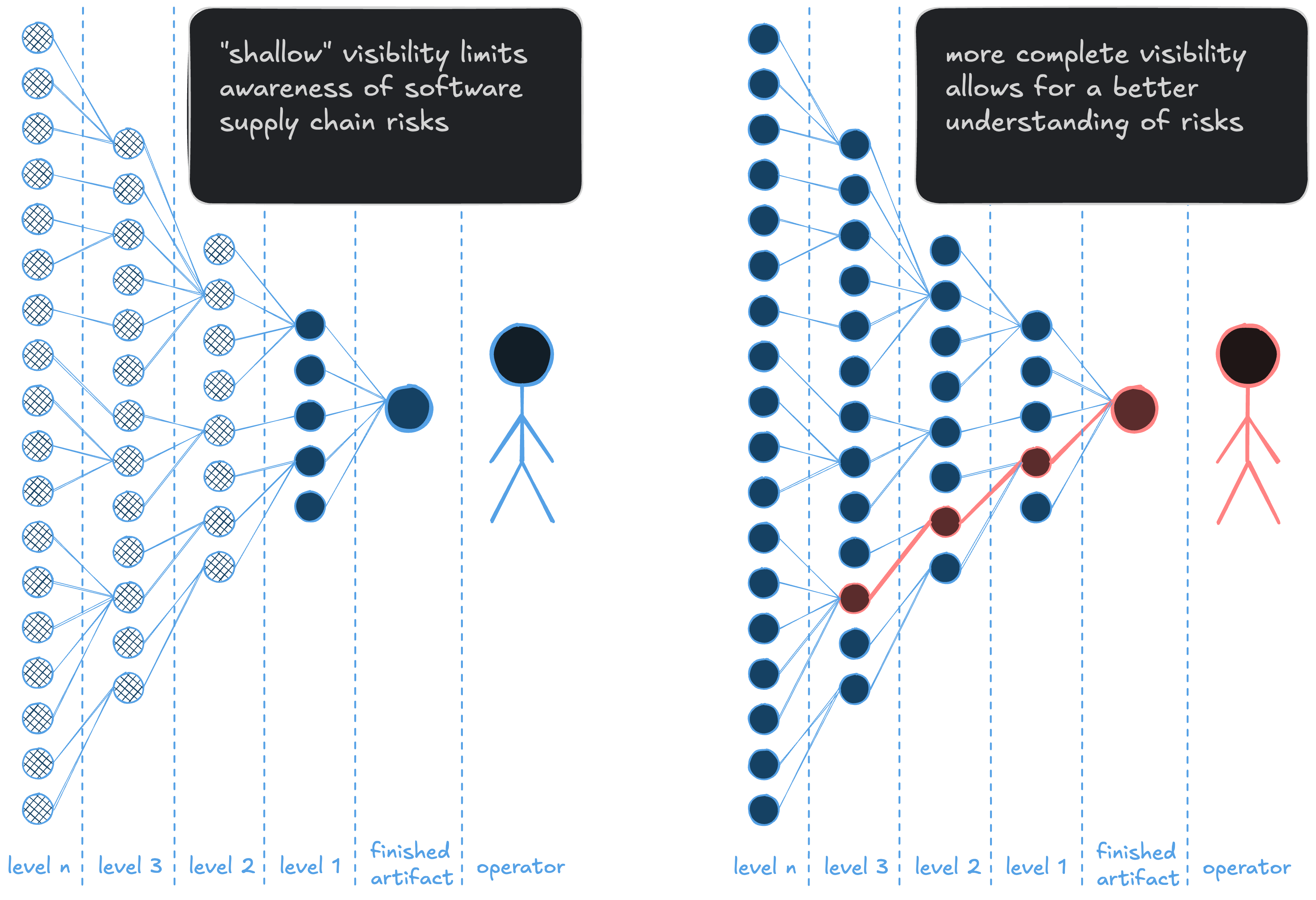
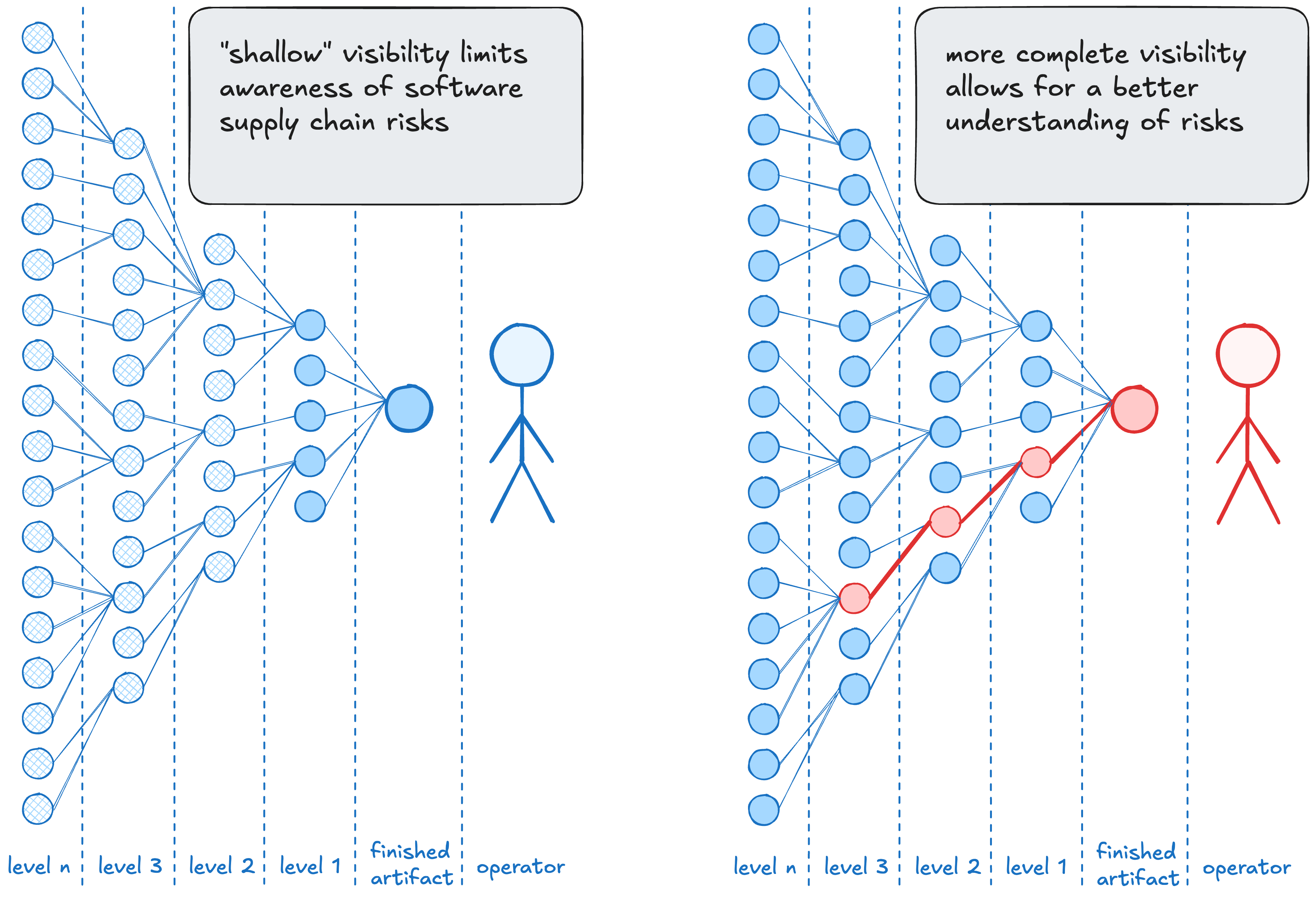 this diagram, outlining “how deep should an SBOM go?”, is from this 2019 NTIA report
this diagram, outlining “how deep should an SBOM go?”, is from this 2019 NTIA report
This depth and understanding of risk is best shown by the diagram above. In both cases, the finished artifact has a vulnerable dependency, but the person on the left doesn’t know that and the one on the right does. Choosing the right place to put trust in the software we’re running is a tradeoff between effort (building is a lot of hard work) and expediency. Being deliberate with trust is choosing where to accept risk.

End of life means end of life
Please stop running end of life software. Kill it, or move the data to something else, or invest in maintaining it yourself. Just … stop running things that won’t ever be fixed. Backporting and cherry-picking patches is a ton of work. It’s equally tons of testing to make sure those fixes didn’t break the functionality the program depends on, introduce other bugs, or degrade performance.
Is this work worth company investment?
Choose the work taken on with the limited bandwidth you have to move the mission forward.
We came to this point by acknowledging that open source software was better than what could be done in-house without substantial investment … so why invest in keeping dead, insecure systems on life support now?
Code review is your friend
Declarative builds are reviewable, two-party-approvable, testable code. Everything needed to reproduce the build can be explicitly declared, from the compiler options to dependencies to inputs that go into the build. It also can go through code review, meaning that no one person can create a production change. There’s much more to talk to on reproducibility, but writing things down is the first stepping stone to take on that journey. It allows the end product to show the work taken to make it, then for you to independently verify it.
Doing things right is hard, but makes life easy
None of these things are easy, but they are simple. It makes many of the harder parts of vulnerability management and compliance simpler to do though. A software bill of material (SBOM) becomes an easy afterthought to create during build, then attest to. Regression testing becomes simple to write and scale for each iteration for production speed and safety. These tests are investments in speed and resiliency, shared across many teams.
It also makes it easier to test and roll out bigger changes to infrastructure security. Containers are one of the best places to start. While it’s easy to say they should never have a shell or a package manager, these changes take time to roll back when many teams rely on doing things unsafely.
🕊️ This is an opportunity to invest in cooperation between teams. 🕊️
Pitfall: The temptation of shortcuts

There’s a lot of places to take shortcuts, though. From bureaucratic shortcuts like simply accepting the risk to technical shortcuts like image slimmers that promise instant improvement with no effort, there’s no shortage of ways to exchange a less effort for more risk.
Here’s a few common places I see teams struggle to quantify that trade-off:
- The project is abandoned, but we really need it
- Using unsafe options like
--privilegedrather than working towards safer paths - Forget to update the “golden dip” process, losing knowledge on how to maintain it
- Disinvestment in the project, making the images less maintained and the team less responsive to user needs
We’ve always had paved paths

What does “W14x22” or “H/6/S/60” mean to you?
Standardization means we can design with known dimensions, strengths and weaknesses, and costs. The lifespan of standard materials are well-known. This allows everyone to forecast costs well into the future. Turns out this is important!
- Many parties work on the design and implementation of a complex thing.
- These parties often do not agree or even like each other very much.
- It costs millions of dollars to design.
- And millions of dollars to operate and maintain.
- It lasts a finite amount of time.
- Lives depend on it.
Oh hey, this is supposed to be a software talk. Turns out civil engineering wasn’t that far from software engineering.
Golden images, well-maintained, can be the same standard good your teams rely on for engineering. It can even make your teams and your company better too! 💖

Disclosure
This is my first try at sponsored content, as my employer was a sponsor of the event … the stories are the same, but with a different format. I work at Chainguard as a solutions engineer at the time of writing this. All opinions are my own. This was drawn from my own experiences building and guiding similar programs with large, heavily regulated teams. 👷🏻♀️