End-to-end testing for custom GitHub Actions runners in Kubernetes
It’s been a minute since I’ve done much with custom GitHub Actions runners, but I’ve still been merging Dependabot PRs and otherwise keeping the lights on. While I wrote a few tests, there’s been no work in expanding the test coverage. The underlying assumption of those tests is that the self-hosted cluster is persistent, but the deployments of test runners are not.
💡 Let’s do a better job keeping the lights on. This will let us safely hand over bumping dependencies that are difficult to automate to AI later on too … 🤖
The end of this moves custom runner image testing to be ephemeral on GitHub’s hosted runners. It uses a pair of cluster configuration files, a helm deployment file, a GitHub Actions workflow file, and hopefully better test coverage. Links above for the impatient.
Why change?
🙊 My Kubernetes cluster hasn’t been persistent, so the tests have been failing for a while. The lack of testing meant I’d not really understood how each update may have affected functionality, apart from some manual testing if I had the time. In order to spend even less time maintaining it, let’s use GitHub’s ephemeral hosted runners to test our self-hosted ones with minikube . This also improves the security posture of our runner deployment by segregating our testing workloads from production.
First, this test should run whenever anything in the Dockerfile is changed or the test workflow changes.
1
2
3
4
5
6
7
8
9
10
11
name: 🧪 Test Wolfi runner
on:
workflow_dispatch:
pull_request:
branches:
- main
paths:
- "images/wolfi.Dockerfile"
- "images/**.sh" # software installer scripts
- ".github/workflows/test-wolfi.yml"
Note that it won’t trigger if you update any of the tests. You’ll have to call the test in a PR to make it run, allowing tests to be worked on without impacting any work on the images until it’s ready.
Build and push the new image to test
There isn’t too much going on here, but in short we’ll checkout the code, login to the container registry, and build the test image using a tag called test.
The full file is here , and is worth looking over as we’ll omit parts like creating pretty output.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
jobs:
build:
name: Build test image
runs-on: ubuntu-latest # use the GitHub-hosted runner to build the image
steps:
- name: Checkout
uses: actions/checkout@de0fac2e4500dabe0009e67214ff5f5447ce83dd # v6.0.2
- name: Login to GHCR
uses: docker/login-action@c94ce9fb468520275223c153574b00df6fe4bcc9 # v3.7.0
with:
registry: ghcr.io
username: ${{ github.actor }}
password: ${{ secrets.GITHUB_TOKEN }}
- name: Build and push
uses: docker/build-push-action@10e90e3645eae34f1e60eeb005ba3a3d33f178e8 # v6.19.2
with:
file: "images/wolfi.Dockerfile"
push: true
tags: ghcr.io/some-natalie/kubernoodles/wolfi:test
Deploy a brand new cluster every time
The full list of tasks is in the deploy job (link ), but in short, this job has a lot of ordered steps. These steps were written down for creating a new cluster … now we’re just creating a new cluster each and every test run.
- Only start once the image successfully is built. It’s possible to put other checks here too, but I haven’t done this.
- Check out the code.
- Set up minikube.
- Create the necessary namespaces.
- Apply the runner role cluster config with the service account it’ll need to run container hooks .
- Create the storage class needed for this inside of minikube.
- Install Helm.
- Install the actions-runner-controller helm chart.
- Install the test runner deployment using a stored secret.
- Sleep for 5 minutes (to allow the tests to run the new runner deployment).
- Tear down the deployment.
The sleep step is weirdly the most important due to how the hosted runners work. The job cannot exit while the cluster is up, testing the new images. If it did, the orchestrator behind the ephemeral host would reap the VM our cluster was running on before it could run the tests we need. 🤦🏻♀️
Run tests targeting that new image
From here, it’s an additional step in the same workflow to target this test deployment with as many tests as you’d like. For now, I didn’t change the test coverage. It checks that sudo works or doesn’t work, that the runner can accept jobs, and that’s about it.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
test:
name: Run tests!
runs-on: [test-wolfi] # test the new changes
needs: [build] # but the build must succeed first
timeout-minutes: 5
steps:
- name: Setup test summary
run: |
echo '### Test summary 🧪' >> $GITHUB_STEP_SUMMARY
echo ' ' >> $GITHUB_STEP_SUMMARY
echo '- ✅ runner builds and deploys' >> $GITHUB_STEP_SUMMARY
- name: Checkout # implicitly tests that JavaScript Actions work
uses: actions/checkout@de0fac2e4500dabe0009e67214ff5f5447ce83dd # v6.0.2
- name: Print debug info
uses: ./tests/debug
- name: Sudo fails
uses: ./tests/sudo-fails
It’s simple to add tests or to refactor this to run tests in parallel. The only caveat is that all of the tests cannot rely on the deployment being successful. You may also need to adjust the sleep statement in the deployment workflow and test timeouts to allow more tests longer to run.
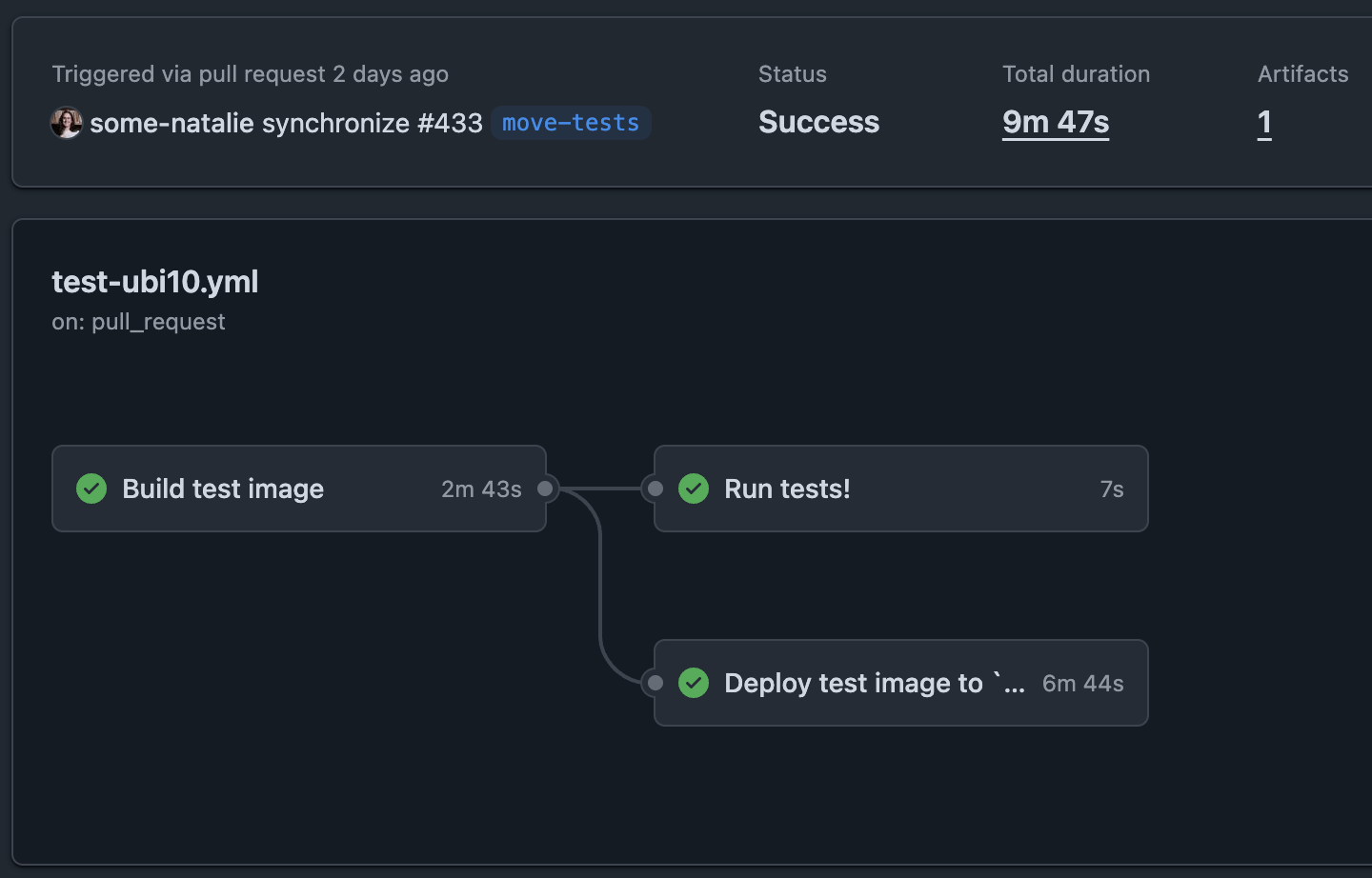
 how the build, deployment, and tests end up depending on each other
how the build, deployment, and tests end up depending on each other
Parting thoughts
It’s nice to not have to maintain a dedicated cluster for these runners. ☺️
Now tests are easier to add, including tests of the helm charts and actions-runner-controller updates as well as the runner images. I’d like to automate updating these as well, so having some basic acceptance tests allows that to happen safely.
This still has some small risks from the rogue Actions in the ecosystem potentially trying to dump private keys and the like. These should be mostly mitigated by pinning everything to a SHA, scoping the secret to only manage runners, and the fact that the cluster doesn’t live long either.
For my regulated crowd, there’s some benefits to this arrangement too. It allows you to update software, test it first, then import your (mostly) finished custom runners. You’ll need to change the SSL certificates and perhaps a few more small items. These changes are low risk and simple to automate. Doing so means the bulk of changes and updates have been tested to work before moving to a more controlled network.
Next up, running these tests when AI is bumping dependencies too.